|
ViennaCL - The Vienna Computing Library
1.7.1
Free open-source GPU-accelerated linear algebra and solver library.
|


|
|
ViennaCL - The Vienna Computing Library
1.7.1
Free open-source GPU-accelerated linear algebra and solver library.
|
|
Main namespace in ViennaCL. Holds all the basic types such as vector, matrix, etc. and defines operations upon them. More...
Namespaces | |
| backend | |
| Namespace providing routines for handling the different memory domains. | |
| detail | |
| Holds implementation details for functionality in the main viennacl-namespace. Not intended for direct use by library users. | |
| device_specific | |
| Provides an OpenCL kernel generator. | |
| io | |
| Provides basic input-output functionality. | |
| linalg | |
| Provides all linear algebra operations which are not covered by operator overloads. | |
| ocl | |
| OpenCL backend. Manages platforms, contexts, buffers, kernels, etc. | |
| result_of | |
| Namespace containing many meta-functions. | |
| scheduler | |
| Contains the scheduling functionality which allows for dynamic kernel generation as well as the fusion of multiple statements into a single kernel. | |
| tools | |
| Namespace for various tools used within ViennaCL. | |
| traits | |
| Namespace providing traits-information as well as generic wrappers to common routines for vectors and matrices such as size() or clear() | |
Classes | |
| class | advanced_cuthill_mckee_tag |
| Tag for the advanced Cuthill-McKee algorithm (i.e. running the 'standard' Cuthill-McKee algorithm for a couple of different seeds). More... | |
| class | basic_range |
| A range class that refers to an interval [start, stop), where 'start' is included, and 'stop' is excluded. More... | |
| class | basic_slice |
| A slice class that refers to an interval [start, stop), where 'start' is included, and 'stop' is excluded. More... | |
| class | circulant_matrix |
| A Circulant matrix class. More... | |
| struct | col_iteration |
| A tag indicating iteration along increasing columns index of a matrix. More... | |
| struct | column_major |
| A tag for column-major storage of a dense matrix. More... | |
| struct | column_major_tag |
| Tag class for indicating column-major layout of a matrix. Not passed to the matrix directly, see row_major type. More... | |
| class | compressed_compressed_matrix |
| A sparse square matrix in compressed sparse rows format optimized for the case that only a few rows carry nonzero entries. More... | |
| class | compressed_matrix |
| A sparse square matrix in compressed sparse rows format. More... | |
| class | const_entry_proxy |
| A proxy class for a single element of a vector or matrix. This proxy should not be noticed by end-users of the library. More... | |
| class | const_vector_iterator |
| A STL-type const-iterator for vector elements. Elements can be accessed, but cannot be manipulated. VERY SLOW!! More... | |
| class | context |
| Represents a generic 'context' similar to an OpenCL context, but is backend-agnostic and thus also suitable for CUDA and OpenMP. More... | |
| class | coordinate_matrix |
| A sparse square matrix, where entries are stored as triplets (i,j, val), where i and j are the row and column indices and val denotes the entry. More... | |
| class | cuda_not_available_exception |
| struct | cuthill_mckee_tag |
| A tag class for selecting the Cuthill-McKee algorithm for reducing the bandwidth of a sparse matrix. More... | |
| class | ell_matrix |
| Sparse matrix class using the ELLPACK format for storing the nonzeros. More... | |
| struct | enable_if |
| Simple enable-if variant that uses the SFINAE pattern. More... | |
| class | entry_proxy |
| A proxy class for a single element of a vector or matrix. This proxy should not be noticed by end-users of the library. More... | |
| struct | gibbs_poole_stockmeyer_tag |
| Tag class for identifying the Gibbs-Poole-Stockmeyer algorithm for reducing the bandwidth of a sparse matrix. More... | |
| class | hankel_matrix |
| A Hankel matrix class. More... | |
| class | hyb_matrix |
| Sparse matrix class using a hybrid format composed of the ELL and CSR format for storing the nonzeros. More... | |
| class | identity_matrix |
| Represents a vector consisting of 1 at a given index and zeros otherwise. To be used as an initializer for viennacl::vector, vector_range, or vector_slize only. More... | |
| class | implicit_matrix_base |
| Base class for representing matrices where the individual entries are not all stored explicitly, e.g. identity_matrix<> More... | |
| class | implicit_vector_base |
| Common base class for representing vectors where the entries are not all stored explicitly. More... | |
| struct | is_addition |
| Helper metafunction for checking whether the provided type is viennacl::op_add (for addition) More... | |
| struct | is_any_dense_matrix |
| Checks for either matrix_base or implicit_matrix_base. More... | |
| struct | is_any_dense_structured_matrix |
| Helper class for checking whether the provided type is any of the dense structured matrix types (circulant, Hankel, etc.) More... | |
| struct | is_any_scalar |
| Helper struct for checking whether the provided type represents a scalar (either host, from ViennaCL, or a flip-sign proxy) More... | |
| struct | is_any_sparse_matrix |
| Helper class for checking whether the provided type is one of the sparse matrix types (compressed_matrix, coordinate_matrix, etc.) More... | |
| struct | is_any_vector |
| Checks for a type being either vector_base or implicit_vector_base. More... | |
| struct | is_circulant_matrix |
| Helper class for checking whether a matrix is a circulant matrix. More... | |
| struct | is_compressed_matrix |
| Helper class for checking whether a matrix is a compressed_matrix (CSR format) More... | |
| struct | is_coordinate_matrix |
| Helper class for checking whether a matrix is a coordinate_matrix (COO format) More... | |
| struct | is_cpu_scalar |
| Helper struct for checking whether a type is a host scalar type (e.g. float, double) More... | |
| struct | is_division |
| Helper metafunction for checking whether the provided type is viennacl::op_div (for division) More... | |
| struct | is_eigen |
| Meta function which checks whether a tag is tag_eigen. More... | |
| struct | is_ell_matrix |
| Helper class for checking whether a matrix is an ell_matrix (ELL format) More... | |
| struct | is_flip_sign_scalar |
| Helper struct for checking whether a type represents a sign flip on a viennacl::scalar<> More... | |
| struct | is_hankel_matrix |
| Helper class for checking whether a matrix is a Hankel matrix. More... | |
| struct | is_hyb_matrix |
| Helper class for checking whether a matrix is a hyb_matrix (hybrid format: ELL plus CSR) More... | |
| struct | is_mtl4 |
| Meta function which checks whether a tag is tag_mtl4. More... | |
| struct | is_primitive_type |
| Helper class for checking whether a type is a primitive type. More... | |
| struct | is_product |
| Helper metafunction for checking whether the provided type is viennacl::op_prod (for products/multiplication) More... | |
| struct | is_row_major |
| Helper class for checking whether a matrix has a row-major layout. More... | |
| struct | is_scalar |
| Helper struct for checking whether a type is a viennacl::scalar<> More... | |
| struct | is_sliced_ell_matrix |
Helper class for checking whether a matrix is a sliced_ell_matrix (SELL-C- 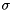 format) More... format) More... | |
| struct | is_stl |
| Meta function which checks whether a tag is tag_ublas. More... | |
| struct | is_subtraction |
| Helper metafunction for checking whether the provided type is viennacl::op_sub (for subtraction) More... | |
| struct | is_toeplitz_matrix |
| Helper class for checking whether a matrix is a Toeplitz matrix. More... | |
| struct | is_ublas |
| Meta function which checks whether a tag is tag_ublas. More... | |
| struct | is_vandermonde_matrix |
| Helper class for checking whether a matrix is a Vandermonde matrix. More... | |
| struct | is_viennacl |
| Meta function which checks whether a tag is tag_viennacl. More... | |
| class | matrix |
| A dense matrix class. More... | |
| class | matrix_base |
| class | matrix_expression |
| Expression template class for representing a tree of expressions which ultimately result in a matrix. More... | |
| class | matrix_iterator |
| A dense matrix class. More... | |
| class | matrix_range |
| Class for representing non-strided submatrices of a bigger matrix A. More... | |
| class | matrix_range< matrix_range< MatrixType > > |
| class | matrix_slice |
| Class for representing strided submatrices of a bigger matrix A. More... | |
| class | matrix_slice< matrix_range< MatrixType > > |
| class | memory_exception |
| Exception class in case of memory errors. More... | |
| struct | one_vector |
| struct | op_abs |
| A tag class representing the modulus function for integers. More... | |
| struct | op_acos |
| A tag class representing the acos() function. More... | |
| struct | op_add |
| A tag class representing addition. More... | |
| struct | op_argmax |
| A tag class for representing the argmax() function. More... | |
| struct | op_argmin |
| A tag class for representing the argmin() function. More... | |
| struct | op_asin |
| A tag class representing the asin() function. More... | |
| struct | op_assign |
| A tag class representing assignment. More... | |
| struct | op_atan |
| A tag class representing the atan() function. More... | |
| struct | op_atan2 |
| A tag class representing the atan2() function. More... | |
| struct | op_ceil |
| A tag class representing the ceil() function. More... | |
| struct | op_col_sum |
| A tag class representing the summation of all columns of a matrix. More... | |
| struct | op_column |
| A tag class representing the extraction of a matrix column to a vector. More... | |
| struct | op_cos |
| A tag class representing the cos() function. More... | |
| struct | op_cosh |
| A tag class representing the cosh() function. More... | |
| struct | op_div |
| A tag class representing division. More... | |
| struct | op_element_binary |
| A tag class representing element-wise binary operations (like multiplication) on vectors or matrices. More... | |
| struct | op_element_cast |
| A tag class representing element-wise casting operations on vectors and matrices. More... | |
| struct | op_element_unary |
| A tag class representing element-wise unary operations (like sin()) on vectors or matrices. More... | |
| struct | op_eq |
| A tag class representing equality. More... | |
| struct | op_exp |
| A tag class representing the exp() function. More... | |
| struct | op_fabs |
| A tag class representing the fabs() function. More... | |
| struct | op_fdim |
| A tag class representing the fdim() function. More... | |
| struct | op_flip_sign |
| A tag class representing sign flips (for scalars only. Vectors and matrices use the standard multiplication by the scalar -1.0) More... | |
| struct | op_floor |
| A tag class representing the floor() function. More... | |
| struct | op_fmax |
| A tag class representing the fmax() function. More... | |
| struct | op_fmin |
| A tag class representing the fmin() function. More... | |
| struct | op_fmod |
| A tag class representing the fmod() function. More... | |
| struct | op_geq |
| A tag class representing greater-than-or-equal-to. More... | |
| struct | op_greater |
| A tag class representing greater-than. More... | |
| struct | op_inner_prod |
| A tag class representing inner products of two vectors. More... | |
| struct | op_inplace_add |
| A tag class representing inplace addition. More... | |
| struct | op_inplace_sub |
| A tag class representing inplace subtraction. More... | |
| struct | op_leq |
| A tag class representing less-than-or-equal-to. More... | |
| struct | op_less |
| A tag class representing less-than. More... | |
| struct | op_log |
| A tag class representing the log() function. More... | |
| struct | op_log10 |
| A tag class representing the log10() function. More... | |
| struct | op_mat_mat_prod |
| A tag class representing matrix-matrix products. More... | |
| struct | op_matrix_diag |
| A tag class representing the (off-)diagonal of a matrix. More... | |
| struct | op_max |
| A tag class representing the maximum of a vector. More... | |
| struct | op_min |
| A tag class representing the minimum of a vector. More... | |
| struct | op_mult |
| A tag class representing multiplication by a scalar. More... | |
| struct | op_neq |
| A tag class representing inequality. More... | |
| struct | op_norm_1 |
| A tag class representing the 1-norm of a vector. More... | |
| struct | op_norm_2 |
| A tag class representing the 2-norm of a vector. More... | |
| struct | op_norm_frobenius |
| A tag class representing the Frobenius-norm of a matrix. More... | |
| struct | op_norm_inf |
| A tag class representing the inf-norm of a vector. More... | |
| struct | op_pow |
| A tag class representing the power function. More... | |
| struct | op_prod |
| A tag class representing matrix-vector products and element-wise multiplications. More... | |
| struct | op_row |
| A tag class representing the extraction of a matrix row to a vector. More... | |
| struct | op_row_sum |
| A tag class representing the summation of all rows of a matrix. More... | |
| struct | op_sin |
| A tag class representing the sin() function. More... | |
| struct | op_sinh |
| A tag class representing the sinh() function. More... | |
| struct | op_sqrt |
| A tag class representing the sqrt() function. More... | |
| struct | op_sub |
| A tag class representing subtraction. More... | |
| struct | op_sum |
| A tag class representing the summation of a vector. More... | |
| struct | op_tan |
| A tag class representing the tan() function. More... | |
| struct | op_tanh |
| A tag class representing the tanh() function. More... | |
| struct | op_trans |
| A tag class representing transposed matrices. More... | |
| struct | op_vector_diag |
| A tag class representing a matrix given by a vector placed on a certain (off-)diagonal. More... | |
| struct | row_iteration |
| A tag indicating iteration along increasing row index of a matrix. More... | |
| struct | row_major |
| A tag for row-major storage of a dense matrix. More... | |
| struct | row_major_tag |
| Tag class for indicating row-major layout of a matrix. Not passed to the matrix directly, see row_major type. More... | |
| class | scalar |
| This class represents a single scalar value on the GPU and behaves mostly like a built-in scalar type like float or double. More... | |
| class | scalar_expression |
| A proxy for scalar expressions (e.g. from inner vector products) More... | |
| class | scalar_expression< LHS, RHS, op_inner_prod > |
| Specialization of a scalar expression for inner products. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_max > |
| Specialization of a scalar expression for max(). Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_min > |
| Specialization of a scalar expression for norm_inf. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_norm_1 > |
| Specialization of a scalar expression for norm_1. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_norm_2 > |
| Specialization of a scalar expression for norm_2. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_norm_frobenius > |
| Specialization of a scalar expression for norm_frobenius. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_norm_inf > |
| Specialization of a scalar expression for norm_inf. Allows for a final reduction on the CPU. More... | |
| class | scalar_expression< LHS, RHS, op_sum > |
| Specialization of a scalar expression for norm_inf. Allows for a final reduction on the CPU. More... | |
| class | scalar_matrix |
| Represents a vector consisting of scalars 's' only, i.e. v[i] = s for all i. To be used as an initializer for viennacl::vector, vector_range, or vector_slize only. More... | |
| struct | scalar_vector |
| Represents a vector consisting of scalars 's' only, i.e. v[i] = s for all i. To be used as an initializer for viennacl::vector, vector_range, or vector_slize only. More... | |
| class | sliced_ell_matrix |
| Sparse matrix class using the sliced ELLPACK with parameters C, . More... | |
| struct | tag_eigen |
| A tag class for identifying types from Eigen. More... | |
| struct | tag_mtl4 |
| A tag class for identifying types from MTL4. More... | |
| struct | tag_none |
| A tag class for identifying 'unknown' types. More... | |
| struct | tag_stl |
| A tag class for identifying types from the C++ STL. More... | |
| struct | tag_ublas |
| A tag class for identifying types from uBLAS. More... | |
| struct | tag_viennacl |
| A tag class for identifying types from ViennaCL. More... | |
| class | toeplitz_matrix |
| A Toeplitz matrix class. More... | |
| struct | unit_vector |
| Represents a vector consisting of 1 at a given index and zeros otherwise. More... | |
| class | unknown_norm_exception |
| class | vandermonde_matrix |
| A Vandermonde matrix class. More... | |
| class | vector |
| class | vector_base |
| Common base class for dense vectors, vector ranges, and vector slices. More... | |
| class | vector_expression |
| An expression template class that represents a binary operation that yields a vector. More... | |
| class | vector_iterator |
| A STL-type iterator for vector elements. Elements can be accessed and manipulated. VERY SLOW!! More... | |
| class | vector_range |
| Class for representing non-strided subvectors of a bigger vector x. More... | |
| class | vector_range< vector_range< VectorType > > |
| class | vector_slice |
| Class for representing strided subvectors of a bigger vector x. More... | |
| class | vector_slice< vector_slice< VectorType > > |
| class | vector_tuple |
| Tuple class holding pointers to multiple vectors. Mainly used as a temporary object returned from viennacl::tie(). More... | |
| class | zero_matrix |
| Represents a vector consisting of zeros only. To be used as an initializer for viennacl::vector, vector_range, or vector_slize only. More... | |
| class | zero_on_diagonal_exception |
| struct | zero_vector |
Typedefs | |
| typedef std::size_t | vcl_size_t |
| typedef std::ptrdiff_t | vcl_ptrdiff_t |
| typedef basic_range | range |
| typedef basic_slice | slice |
Enumerations | |
| enum | memory_types { MEMORY_NOT_INITIALIZED, MAIN_MEMORY, OPENCL_MEMORY, CUDA_MEMORY } |
Functions | |
| template<typename T > | |
| void | switch_memory_context (T &obj, viennacl::context new_ctx) |
| Generic convenience routine for migrating data of an object to a new memory domain. More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< NumericT > &cpu_vec, circulant_matrix< NumericT, AlignmentV > &gpu_mat) |
| Copies a circulant matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (circulant_matrix< NumericT, AlignmentV > &gpu_mat, std::vector< NumericT > &cpu_vec) |
| Copies a circulant matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (circulant_matrix< NumericT, AlignmentV > &circ_src, MatrixT &com_dst) |
| Copies a circulant matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (MatrixT &com_src, circulant_matrix< NumericT, AlignmentV > &circ_dst) |
| Copies a the matrix-like object to the circulant matrix from the OpenCL device (either GPU or multi-core CPU) More... | |
| template<class NumericT , unsigned int AlignmentV> | |
| std::ostream & | operator<< (std::ostream &s, circulant_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Prints the matrix. Output is compatible to boost::numeric::ublas. More... | |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const CPUMatrixT &cpu_matrix, compressed_compressed_matrix< NumericT > &gpu_matrix) |
| Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename SizeT , typename NumericT > | |
| void | copy (const std::vector< std::map< SizeT, NumericT > > &cpu_matrix, compressed_compressed_matrix< NumericT > &gpu_matrix) |
| Copies a sparse square matrix in the std::vector< std::map < > > format to an OpenCL device. Use viennacl::tools::sparse_matrix_adapter for non-square matrices. More... | |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const compressed_compressed_matrix< NumericT > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host. More... | |
| template<typename NumericT > | |
| void | copy (const compressed_compressed_matrix< NumericT > &gpu_matrix, std::vector< std::map< unsigned int, NumericT > > &cpu_matrix) |
| Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format . More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const CPUMatrixT &cpu_matrix, compressed_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename SizeT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const std::vector< std::map< SizeT, NumericT > > &cpu_matrix, compressed_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse square matrix in the std::vector< std::map < > > format to an OpenCL device. Use viennacl::tools::sparse_matrix_adapter for non-square matrices. More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const compressed_matrix< NumericT, AlignmentV > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host. More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (const compressed_matrix< NumericT, AlignmentV > &gpu_matrix, std::vector< std::map< unsigned int, NumericT > > &cpu_matrix) |
| Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format . More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| std::ostream & | operator<< (std::ostream &os, compressed_matrix< NumericT, AlignmentV > const &A) |
| Output stream support for compressed_matrix. Output format is same as MATLAB, Octave, or SciPy. More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const CPUMatrixT &cpu_matrix, coordinate_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (const std::vector< std::map< unsigned int, NumericT > > &cpu_matrix, coordinate_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse matrix in the std::vector< std::map < > > format to an OpenCL device. More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const coordinate_matrix< NumericT, AlignmentV > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host. More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (const coordinate_matrix< NumericT, AlignmentV > &gpu_matrix, std::vector< std::map< unsigned int, NumericT > > &cpu_matrix) |
| Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format . More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const CPUMatrixT &cpu_matrix, ell_matrix< NumericT, AlignmentV > &gpu_matrix) |
| template<typename IndexT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< std::map< IndexT, NumericT > > const &cpu_matrix, ell_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format . More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const ell_matrix< NumericT, AlignmentV > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| template<typename NumericT , unsigned int AlignmentV, typename IndexT > | |
| void | copy (const ell_matrix< NumericT, AlignmentV > &gpu_matrix, std::vector< std::map< IndexT, NumericT > > &cpu_matrix) |
| Copies a sparse matrix from the compute device to the host. The host type is the std::vector< std::map < > > format . More... | |
| template<typename SCALARTYPE , unsigned int ALIGNMENT, typename CPU_ITERATOR > | |
| void | copy (CPU_ITERATOR const &cpu_begin, CPU_ITERATOR const &cpu_end, vector_iterator< SCALARTYPE, ALIGNMENT > gpu_begin) |
| template<typename SCALARTYPE , unsigned int ALIGNMENT_SRC, unsigned int ALIGNMENT_DEST> | |
| void | copy (const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const &gpu_src_begin, const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const &gpu_src_end, vector_iterator< SCALARTYPE, ALIGNMENT_DEST > gpu_dest_begin) |
| template<typename SCALARTYPE , unsigned int ALIGNMENT_SRC, unsigned int ALIGNMENT_DEST> | |
| void | copy (const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const &gpu_src_begin, const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const &gpu_src_end, const_vector_iterator< SCALARTYPE, ALIGNMENT_DEST > gpu_dest_begin) |
| template<typename SCALARTYPE , unsigned int ALIGNMENT, typename CPU_ITERATOR > | |
| void | fast_copy (const const_vector_iterator< SCALARTYPE, ALIGNMENT > &gpu_begin, const const_vector_iterator< SCALARTYPE, ALIGNMENT > &gpu_end, CPU_ITERATOR cpu_begin) |
| template<typename CPU_ITERATOR , typename SCALARTYPE , unsigned int ALIGNMENT> | |
| void | fast_copy (CPU_ITERATOR const &cpu_begin, CPU_ITERATOR const &cpu_end, vector_iterator< SCALARTYPE, ALIGNMENT > gpu_begin) |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< NumericT > const &cpu_vec, hankel_matrix< NumericT, AlignmentV > &gpu_mat) |
| Copies a Hankel matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (hankel_matrix< NumericT, AlignmentV > const &gpu_mat, std::vector< NumericT > &cpu_vec) |
| Copies a Hankel matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (hankel_matrix< NumericT, AlignmentV > const &han_src, MatrixT &com_dst) |
| Copies a Hankel matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (MatrixT const &com_src, hankel_matrix< NumericT, AlignmentV > &han_dst) |
| Copies a the matrix-like object to the Hankel matrix from the OpenCL device (either GPU or multi-core CPU) More... | |
| template<class NumericT , unsigned int AlignmentV> | |
| std::ostream & | operator<< (std::ostream &s, hankel_matrix< NumericT, AlignmentV > &gpu_matrix) |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const CPUMatrixT &cpu_matrix, hyb_matrix< NumericT, AlignmentV > &gpu_matrix) |
| template<typename IndexT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< std::map< IndexT, NumericT > > const &cpu_matrix, hyb_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format . More... | |
| template<typename CPUMatrixT , typename NumericT , unsigned int AlignmentV> | |
| void | copy (const hyb_matrix< NumericT, AlignmentV > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| template<typename NumericT , unsigned int AlignmentV, typename IndexT > | |
| void | copy (const hyb_matrix< NumericT, AlignmentV > &gpu_matrix, std::vector< std::map< IndexT, NumericT > > &cpu_matrix) |
| Copies a sparse matrix from the compute device to the host. The host type is the std::vector< std::map < > > format . More... | |
| template<typename NumericT > | |
| NumericT * | cuda_arg (scalar< NumericT > &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL scalar. Non-const version. More... | |
| template<typename NumericT > | |
| const NumericT * | cuda_arg (scalar< NumericT > const &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL scalar. Const version. More... | |
| template<typename NumericT > | |
| NumericT * | cuda_arg (vector_base< NumericT > &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base) with implicit return type deduction. Non-const version. More... | |
| template<typename NumericT > | |
| const NumericT * | cuda_arg (vector_base< NumericT > const &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base) with implicit return type deduction. Const version. More... | |
| template<typename ReturnT , typename NumericT > | |
| ReturnT * | cuda_arg (vector_base< NumericT > &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base). Return type needs to be explicitly provided as first template argument. Non-const version. More... | |
| template<typename ReturnT , typename NumericT > | |
| const ReturnT * | cuda_arg (vector_base< NumericT > const &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base). Return type needs to be explicitly provided as first template argument. Const version. More... | |
| template<typename NumericT > | |
| NumericT * | cuda_arg (matrix_base< NumericT > &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL matrix (through the base class matrix_base). Non-const version. More... | |
| template<typename NumericT > | |
| const NumericT * | cuda_arg (matrix_base< NumericT > const &obj) |
| Convenience helper function for extracting the CUDA handle from a ViennaCL matrix (through the base class matrix_base). Const version. More... | |
| template<typename ReturnT > | |
| ReturnT * | cuda_arg (viennacl::backend::mem_handle &h) |
| Convenience helper function for extracting the CUDA handle from a generic memory handle. Non-const version. More... | |
| template<typename ReturnT > | |
| ReturnT const * | cuda_arg (viennacl::backend::mem_handle const &h) |
| Convenience helper function for extracting the CUDA handle from a generic memory handle. Const-version. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator+= (vector_base< NumericT > &v1, const viennacl::vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, viennacl::op_prod > &proxy) |
| Implementation of the operation v1 += A * v2, where A is a matrix. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator-= (vector_base< NumericT > &v1, const viennacl::vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, viennacl::op_prod > &proxy) |
| Implementation of the operation v1 -= A * v2, where A is a matrix. More... | |
| template<typename NumericT > | |
| viennacl::vector< NumericT > | operator+ (const vector_base< NumericT > &v1, const vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation 'result = v1 + A * v2', where A is a matrix. More... | |
| template<typename NumericT > | |
| viennacl::vector< NumericT > | operator- (const vector_base< NumericT > &v1, const vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation 'result = v1 - A * v2', where A is a matrix. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator+= (vector_base< NumericT > &v1, const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation v1 += A * v2, where A is a matrix. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator-= (vector_base< NumericT > &v1, const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation v1 -= A * v2, where A is a matrix. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator+ (const vector_base< NumericT > &v1, const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation 'result = v1 + A * v2', where A is a matrix. More... | |
| template<typename NumericT > | |
| vector< NumericT > | operator- (const vector_base< NumericT > &v1, const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > &proxy) |
| Implementation of the operation 'result = v1 - A * v2', where A is a matrix. More... | |
| template<typename M1 > | |
| viennacl::enable_if < viennacl::is_any_sparse_matrix < M1 >::value, matrix_expression< const M1, const M1, op_trans > >::type | trans (const M1 &mat) |
| Returns an expression template class representing a transposed matrix. More... | |
| template<typename SCALARTYPE , typename SparseMatrixType > | |
| viennacl::enable_if < viennacl::is_any_sparse_matrix < SparseMatrixType >::value, viennacl::vector< SCALARTYPE > >::type | operator+ (viennacl::vector_base< SCALARTYPE > &result, const viennacl::vector_expression< const SparseMatrixType, const viennacl::vector_base< SCALARTYPE >, viennacl::op_prod > &proxy) |
| Implementation of the operation 'result = v1 + A * v2', where A is a matrix. More... | |
| template<typename SCALARTYPE , typename SparseMatrixType > | |
| viennacl::enable_if < viennacl::is_any_sparse_matrix < SparseMatrixType >::value, viennacl::vector< SCALARTYPE > >::type | operator- (viennacl::vector_base< SCALARTYPE > &result, const viennacl::vector_expression< const SparseMatrixType, const viennacl::vector_base< SCALARTYPE >, viennacl::op_prod > &proxy) |
| Implementation of the operation 'result = v1 - A * v2', where A is a matrix. More... | |
| template<typename T , typename LHS , typename RHS , typename OP > | |
| vector_base< T > & | operator+= (vector_base< T > &v1, const vector_expression< const LHS, const RHS, OP > &proxy) |
| template<typename T , typename LHS , typename RHS , typename OP > | |
| vector_base< T > & | operator-= (vector_base< T > &v1, const vector_expression< const LHS, const RHS, OP > &proxy) |
| template<class NumericT > | |
| std::ostream & | operator<< (std::ostream &s, const matrix_base< NumericT > &gpu_matrix) |
| Prints the matrix. Output is compatible to boost::numeric::ublas. More... | |
| template<typename LHS , typename RHS , typename OP > | |
| std::ostream & | operator<< (std::ostream &s, const matrix_expression< LHS, RHS, OP > &expr) |
| Prints the matrix. Output is compatible to boost::numeric::ublas. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT > , op_trans > | trans (const matrix_base< NumericT > &mat) |
| Returns an expression template class representing a transposed matrix. More... | |
| template<typename LhsT , typename RhsT , typename OpT > | |
| matrix_expression< const matrix_expression< const LhsT, const RhsT, OpT >, const matrix_expression< const LhsT, const RhsT, OpT >, op_trans > | trans (const matrix_expression< const LhsT, const RhsT, OpT > &proxy) |
| Returns an expression template class representing the transposed matrix expression. More... | |
| template<typename NumericT > | |
| vector_expression< const matrix_base< NumericT >, const int, op_matrix_diag > | diag (const matrix_base< NumericT > &A, int k=0) |
| template<typename NumericT > | |
| matrix_expression< const vector_base< NumericT >, const int, op_vector_diag > | diag (const vector_base< NumericT > &v, int k=0) |
| template<typename NumericT , typename F > | |
| vector_expression< const matrix_base< NumericT, F > , const unsigned int, op_row > | row (const matrix_base< NumericT, F > &A, unsigned int i) |
| template<typename NumericT , typename F > | |
| vector_expression< const matrix_base< NumericT, F > , const unsigned int, op_column > | column (const matrix_base< NumericT, F > &A, unsigned int j) |
| template<typename CPUMatrixT , typename NumericT , typename F , unsigned int AlignmentV> | |
| void | copy (const CPUMatrixT &cpu_matrix, matrix< NumericT, F, AlignmentV > &gpu_matrix) |
| Copies a dense matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU) More... | |
| template<typename NumericT , typename A1 , typename A2 , typename F , unsigned int AlignmentV> | |
| void | copy (const std::vector< std::vector< NumericT, A1 >, A2 > &cpu_matrix, matrix< NumericT, F, AlignmentV > &gpu_matrix) |
| Copies a dense STL-type matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU) More... | |
| template<typename NumericT , typename F , unsigned int AlignmentV> | |
| void | fast_copy (NumericT *cpu_matrix_begin, NumericT *cpu_matrix_end, matrix< NumericT, F, AlignmentV > &gpu_matrix) |
| Copies a dense matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU) without temporary. Matrix-Layout on CPU must be equal to the matrix-layout on the GPU. More... | |
| template<typename CPUMatrixT , typename NumericT , typename F , unsigned int AlignmentV> | |
| void | copy (const matrix< NumericT, F, AlignmentV > &gpu_matrix, CPUMatrixT &cpu_matrix) |
| Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU). More... | |
| template<typename NumericT , typename A1 , typename A2 , typename F , unsigned int AlignmentV> | |
| void | copy (const matrix< NumericT, F, AlignmentV > &gpu_matrix, std::vector< std::vector< NumericT, A1 >, A2 > &cpu_matrix) |
| Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU). More... | |
| template<typename NumericT , typename F , unsigned int AlignmentV> | |
| void | fast_copy (const matrix< NumericT, F, AlignmentV > &gpu_matrix, NumericT *cpu_matrix_begin) |
| Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU). More... | |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename LHS2 , typename RHS2 , typename OP2 > | |
| matrix_expression< const matrix_expression< const LHS1, const RHS1, OP1 >, const matrix_expression< const LHS2, const RHS2, OP2 >, op_add > | operator+ (matrix_expression< const LHS1, const RHS1, OP1 > const &proxy1, matrix_expression< const LHS2, const RHS2, OP2 > const &proxy2) |
| Generic 'catch-all' overload, which enforces a temporary if the expression tree gets too deep. More... | |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename NumericT > | |
| matrix_expression< const matrix_expression< const LHS1, const RHS1, OP1 >, const matrix_base< NumericT > , op_add > | operator+ (matrix_expression< const LHS1, const RHS1, OP1 > const &proxy1, matrix_base< NumericT > const &proxy2) |
| template<typename NumericT , typename LHS2 , typename RHS2 , typename OP2 > | |
| matrix_expression< const matrix_base< NumericT >, const matrix_expression< const LHS2, const RHS2, OP2 >, op_add > | operator+ (matrix_base< NumericT > const &proxy1, matrix_expression< const LHS2, const RHS2, OP2 > const &proxy2) |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT > , op_add > | operator+ (const matrix_base< NumericT > &m1, const matrix_base< NumericT > &m2) |
| Operator overload for m1 + m2, where m1 and m2 are either dense matrices, matrix ranges, or matrix slices. No mixing of different storage layouts allowed at the moment. More... | |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename LHS2 , typename RHS2 , typename OP2 > | |
| matrix_expression< const matrix_expression< const LHS1, const RHS1, OP1 >, const matrix_expression< const LHS2, const RHS2, OP2 >, op_sub > | operator- (matrix_expression< const LHS1, const RHS1, OP1 > const &proxy1, matrix_expression< const LHS2, const RHS2, OP2 > const &proxy2) |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename NumericT > | |
| matrix_expression< const matrix_expression< const LHS1, const RHS1, OP1 >, const matrix_base< NumericT > , op_sub > | operator- (matrix_expression< const LHS1, const RHS1, OP1 > const &proxy1, matrix_base< NumericT > const &proxy2) |
| template<typename NumericT , typename LHS2 , typename RHS2 , typename OP2 > | |
| matrix_expression< const matrix_base< NumericT >, const matrix_expression< const LHS2, const RHS2, OP2 >, op_sub > | operator- (matrix_base< NumericT > const &proxy1, matrix_expression< const LHS2, const RHS2, OP2 > const &proxy2) |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT > , op_sub > | operator- (const matrix_base< NumericT > &m1, const matrix_base< NumericT > &m2) |
| Operator overload for m1 - m2, where m1 and m2 are either dense matrices, matrix ranges, or matrix slices. No mixing of different storage layouts allowed at the moment. More... | |
| template<typename S1 , typename NumericT > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_base< NumericT > , const S1, op_mult >>::type | operator* (S1 const &value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a host scalar (float or double) and m1 is a ViennaCL matrix. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (char value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a char (8-bit integer) More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (short value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a short integer. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (int value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is an integer. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (long value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a long integer. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (float value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a single precision floating point value. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (double value, matrix_base< NumericT > const &m1) |
| Operator overload for the expression alpha * m1, where alpha is a double precision floating point value. More... | |
| template<typename LHS , typename RHS , typename OP , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_expression< LHS, RHS, OP >, const S1, op_mult > >::type | operator* (matrix_expression< LHS, RHS, OP > const &proxy, S1 const &val) |
| Operator overload for the multiplication of a matrix expression with a scalar from the right, e.g. (beta * m1) * alpha. Here, beta * m1 is wrapped into a matrix_expression and then multiplied with alpha from the right. More... | |
| template<typename S1 , typename LHS , typename RHS , typename OP > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_expression< LHS, RHS, OP >, const S1, op_mult > >::type | operator* (S1 const &val, matrix_expression< LHS, RHS, OP > const &proxy) |
| Operator overload for the multiplication of a matrix expression with a ViennaCL scalar from the left, e.g. alpha * (beta * m1). Here, beta * m1 is wrapped into a matrix_expression and then multiplied with alpha from the left. More... | |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_base< NumericT > , const S1, op_mult > >::type | operator* (matrix_base< NumericT > const &m1, S1 const &s1) |
| Scales the matrix by a GPU scalar 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, char s1) |
| Scales the matrix by a char (8-bit integer) 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, short s1) |
| Scales the matrix by a short integer 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, int s1) |
| Scales the matrix by an integer 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, long s1) |
| Scales the matrix by a long integer 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, float s1) |
| Scales the matrix by a single precision floating point number 'alpha' and returns an expression template. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_mult > | operator* (matrix_base< NumericT > const &m1, double s1) |
| Scales the matrix by a double precision floating point number 'alpha' and returns an expression template. More... | |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_scalar< S1 > ::value, matrix_base< NumericT > & >::type | operator*= (matrix_base< NumericT > &m1, S1 const &gpu_val) |
| Scales a matrix by a GPU scalar value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, char gpu_val) |
| Scales a matrix by a char (8-bit) value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, short gpu_val) |
| Scales a matrix by a short integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, int gpu_val) |
| Scales a matrix by an integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, long gpu_val) |
| Scales a matrix by a long integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, float gpu_val) |
| Scales a matrix by a single precision floating point value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator*= (matrix_base< NumericT > &m1, double gpu_val) |
| Scales a matrix by a double precision floating point value. More... | |
| template<typename LHS , typename RHS , typename OP , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_expression < const LHS, const RHS, OP > , const S1, op_div > >::type | operator/ (matrix_expression< const LHS, const RHS, OP > const &proxy, S1 const &val) |
| Operator overload for the division of a matrix expression by a scalar from the right, e.g. (beta * m1) / alpha. Here, beta * m1 is wrapped into a matrix_expression and then divided by alpha. More... | |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, matrix_expression < const matrix_base< NumericT > , const S1, op_div > >::type | operator/ (matrix_base< NumericT > const &m1, S1 const &s1) |
| Returns an expression template for scaling the matrix by a GPU scalar 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, char s1) |
| Returns an expression template for scaling the matrix by a char (8-bit integer) 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, short s1) |
| Returns an expression template for scaling the matrix by a short integer 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, int s1) |
| Returns an expression template for scaling the matrix by an integer 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, long s1) |
| Returns an expression template for scaling the matrix by a long integer 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, float s1) |
| Returns an expression template for scaling the matrix by a single precision floating point number 'alpha'. More... | |
| template<typename NumericT > | |
| matrix_expression< const matrix_base< NumericT >, const NumericT, op_div > | operator/ (matrix_base< NumericT > const &m1, double s1) |
| Returns an expression template for scaling the matrix by a double precision floating point number 'alpha'. More... | |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_scalar< S1 > ::value, matrix_base< NumericT > & >::type | operator/= (matrix_base< NumericT > &m1, S1 const &gpu_val) |
| Scales a matrix by a GPU scalar value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, char gpu_val) |
| Scales a matrix by a char (8-bit integer) value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, short gpu_val) |
| Scales a matrix by a short integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, int gpu_val) |
| Scales a matrix by an integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, long gpu_val) |
| Scales a matrix by a long integer value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, float gpu_val) |
| Scales a matrix by a single precision floating point value. More... | |
| template<typename NumericT > | |
| matrix_base< NumericT > & | operator/= (matrix_base< NumericT > &m1, double gpu_val) |
| Scales a matrix by a double precision floating point value. More... | |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_scalar< S1 > ::value, viennacl::matrix_expression < const viennacl::matrix_expression < const vector_base< NumericT > , const vector_base< NumericT > , op_prod >, const S1, op_mult > >::type | operator* (const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy, const S1 &val) |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_cpu_scalar< S1 > ::value, viennacl::matrix_expression < const viennacl::matrix_expression < const vector_base< NumericT > , const vector_base< NumericT > , op_prod >, const NumericT, op_mult >>::type | operator* (const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy, const S1 &val) |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_scalar< S1 > ::value, viennacl::matrix_expression < const viennacl::matrix_expression < const vector_base< NumericT > , const vector_base< NumericT > , op_prod >, const S1, op_mult > >::type | operator* (const S1 &val, const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy) |
| template<typename NumericT , typename S1 > | |
| viennacl::enable_if < viennacl::is_cpu_scalar< S1 > ::value, viennacl::matrix_expression < const viennacl::matrix_expression < const vector_base< NumericT > , const vector_base< NumericT > , op_prod >, const NumericT, op_mult >>::type | operator* (const S1 &val, const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > &proxy) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const CPUMatrixT &cpu_matrix, matrix_range< matrix< NumericT, row_major, 1 > > &gpu_matrix_range) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const CPUMatrixT &cpu_matrix, matrix_range< matrix< NumericT, column_major, 1 > > &gpu_matrix_range) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (matrix_range< matrix< NumericT, row_major, 1 > > const &gpu_matrix_range, CPUMatrixT &cpu_matrix) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (matrix_range< matrix< NumericT, column_major, 1 > > const &gpu_matrix_range, CPUMatrixT &cpu_matrix) |
| template<typename MatrixType > | |
| matrix_range< MatrixType > | project (MatrixType const &A, viennacl::range const &r1, viennacl::range const &r2) |
| template<typename MatrixType > | |
| matrix_range< MatrixType > | project (matrix_range< MatrixType > const &A, viennacl::range const &r1, viennacl::range const &r2) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const CPUMatrixT &cpu_matrix, matrix_slice< matrix< NumericT, row_major, 1 > > &gpu_matrix_slice) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (const CPUMatrixT &cpu_matrix, matrix_slice< matrix< NumericT, column_major, 1 > > &gpu_matrix_slice) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (matrix_slice< matrix< NumericT, row_major, 1 > > const &gpu_matrix_slice, CPUMatrixT &cpu_matrix) |
| template<typename CPUMatrixT , typename NumericT > | |
| void | copy (matrix_slice< matrix< NumericT, column_major, 1 > > const &gpu_matrix_slice, CPUMatrixT &cpu_matrix) |
| template<typename MatrixType > | |
| matrix_slice< MatrixType > | project (MatrixType const &A, viennacl::slice const &r1, viennacl::slice const &r2) |
| template<typename MatrixType > | |
| matrix_slice< MatrixType > | project (matrix_range< MatrixType > const &A, viennacl::slice const &r1, viennacl::slice const &r2) |
| template<typename MatrixType > | |
| matrix_slice< MatrixType > | project (matrix_slice< MatrixType > const &A, viennacl::slice const &r1, viennacl::slice const &r2) |
| template<typename IndexT , typename ValueT > | |
| std::vector< IndexT > | reorder (std::vector< std::map< IndexT, ValueT > > const &matrix, cuthill_mckee_tag) |
| Function for the calculation of a node number permutation to reduce the bandwidth of an incidence matrix by the Cuthill-McKee algorithm. More... | |
| template<typename IndexT , typename ValueT > | |
| std::vector< IndexT > | reorder (std::vector< std::map< IndexT, ValueT > > const &matrix, advanced_cuthill_mckee_tag const &tag) |
| Function for the calculation of a node number permutation to reduce the bandwidth of an incidence matrix by the advanced Cuthill-McKee algorithm. More... | |
| template<typename MatrixType > | |
| std::vector< int > | reorder (MatrixType const &matrix, gibbs_poole_stockmeyer_tag) |
| Function for the calculation of a node numbering permutation vector to reduce the bandwidth of a incidence matrix by the Gibbs-Poole-Stockmeyer algorithm. More... | |
| template<class NumericT > | |
| std::ostream & | operator<< (std::ostream &s, const scalar< NumericT > &val) |
| Allows to directly print the value of a scalar to an output stream. More... | |
| template<class NumericT > | |
| std::istream & | operator>> (std::istream &s, const scalar< NumericT > &val) |
| Allows to directly read a value of a scalar from an input stream. More... | |
| template<typename CPUMatrixT , typename ScalarT , typename IndexT > | |
| void | copy (CPUMatrixT const &cpu_matrix, sliced_ell_matrix< ScalarT, IndexT > &gpu_matrix) |
| template<typename IndexT , typename NumericT , typename IndexT2 > | |
| void | copy (std::vector< std::map< IndexT, NumericT > > const &cpu_matrix, sliced_ell_matrix< NumericT, IndexT2 > &gpu_matrix) |
| Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format . More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< NumericT > const &cpu_vec, toeplitz_matrix< NumericT, AlignmentV > &gpu_mat) |
| Copies a Toeplitz matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (toeplitz_matrix< NumericT, AlignmentV > const &gpu_mat, std::vector< NumericT > &cpu_vec) |
| Copies a Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (toeplitz_matrix< NumericT, AlignmentV > const &tep_src, MatrixT &com_dst) |
| Copies a Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (MatrixT const &com_src, toeplitz_matrix< NumericT, AlignmentV > &tep_dst) |
| Copies a the matrix-like object to the Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU) More... | |
| template<class NumericT , unsigned int AlignmentV> | |
| std::ostream & | operator<< (std::ostream &s, toeplitz_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Prints the matrix. Output is compatible to boost::numeric::ublas. More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (std::vector< NumericT > &cpu_vec, vandermonde_matrix< NumericT, AlignmentV > &gpu_mat) |
| Copies a Vandermonde matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU) More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| void | copy (vandermonde_matrix< NumericT, AlignmentV > &gpu_mat, std::vector< NumericT > &cpu_vec) |
| Copies a Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (vandermonde_matrix< NumericT, AlignmentV > &vander_src, MatrixT &com_dst) |
| Copies a Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename MatrixT > | |
| void | copy (MatrixT &com_src, vandermonde_matrix< NumericT, AlignmentV > &vander_dst) |
| Copies a the matrix-like object to the Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU) More... | |
| template<class NumericT , unsigned int AlignmentV> | |
| std::ostream & | operator<< (std::ostream &s, vandermonde_matrix< NumericT, AlignmentV > &gpu_matrix) |
| Prints the matrix. Output is compatible to boost::numeric::ublas. More... | |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > const &v0, vector_base< ScalarT > const &v1) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > &v0, vector_base< ScalarT > &v1) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > const &v0, vector_base< ScalarT > const &v1, vector_base< ScalarT > const &v2) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > &v0, vector_base< ScalarT > &v1, vector_base< ScalarT > &v2) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > const &v0, vector_base< ScalarT > const &v1, vector_base< ScalarT > const &v2, vector_base< ScalarT > const &v3) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > &v0, vector_base< ScalarT > &v1, vector_base< ScalarT > &v2, vector_base< ScalarT > &v3) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > const &v0, vector_base< ScalarT > const &v1, vector_base< ScalarT > const &v2, vector_base< ScalarT > const &v3, vector_base< ScalarT > const &v4) |
| template<typename ScalarT > | |
| vector_tuple< ScalarT > | tie (vector_base< ScalarT > &v0, vector_base< ScalarT > &v1, vector_base< ScalarT > &v2, vector_base< ScalarT > &v3, vector_base< ScalarT > &v4) |
| template<typename NumericT , unsigned int AlignmentV, typename CPU_ITERATOR > | |
| void | fast_copy (const const_vector_iterator< NumericT, AlignmentV > &gpu_begin, const const_vector_iterator< NumericT, AlignmentV > &gpu_end, CPU_ITERATOR cpu_begin) |
| STL-like transfer of a GPU vector to the CPU. The cpu type is assumed to reside in a linear piece of memory, such as e.g. for std::vector. More... | |
| template<typename NumericT , typename CPUVECTOR > | |
| void | fast_copy (vector_base< NumericT > const &gpu_vec, CPUVECTOR &cpu_vec) |
| Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename CPU_ITERATOR > | |
| void | async_copy (const const_vector_iterator< NumericT, AlignmentV > &gpu_begin, const const_vector_iterator< NumericT, AlignmentV > &gpu_end, CPU_ITERATOR cpu_begin) |
| Asynchronous version of fast_copy(), copying data from device to host. The host iterator cpu_begin needs to reside in a linear piece of memory, such as e.g. for std::vector. More... | |
| template<typename NumericT , typename CPUVECTOR > | |
| void | async_copy (vector_base< NumericT > const &gpu_vec, CPUVECTOR &cpu_vec) |
| Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename CPU_ITERATOR > | |
| void | copy (const const_vector_iterator< NumericT, AlignmentV > &gpu_begin, const const_vector_iterator< NumericT, AlignmentV > &gpu_end, CPU_ITERATOR cpu_begin) |
| STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename CPU_ITERATOR > | |
| void | copy (const vector_iterator< NumericT, AlignmentV > &gpu_begin, const vector_iterator< NumericT, AlignmentV > &gpu_end, CPU_ITERATOR cpu_begin) |
| STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory. More... | |
| template<typename NumericT , typename CPUVECTOR > | |
| void | copy (vector_base< NumericT > const &gpu_vec, CPUVECTOR &cpu_vec) |
| Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());. More... | |
| template<typename CPU_ITERATOR , typename NumericT , unsigned int AlignmentV> | |
| void | fast_copy (CPU_ITERATOR const &cpu_begin, CPU_ITERATOR const &cpu_end, vector_iterator< NumericT, AlignmentV > gpu_begin) |
| STL-like transfer of a CPU vector to the GPU. The cpu type is assumed to reside in a linear piece of memory, such as e.g. for std::vector. More... | |
| template<typename CPUVECTOR , typename NumericT > | |
| void | fast_copy (const CPUVECTOR &cpu_vec, vector_base< NumericT > &gpu_vec) |
| Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());. More... | |
| template<typename CPU_ITERATOR , typename NumericT , unsigned int AlignmentV> | |
| void | async_copy (CPU_ITERATOR const &cpu_begin, CPU_ITERATOR const &cpu_end, vector_iterator< NumericT, AlignmentV > gpu_begin) |
| Asynchronous version of fast_copy(), copying data from host to device. The host iterator cpu_begin needs to reside in a linear piece of memory, such as e.g. for std::vector. More... | |
| template<typename CPUVECTOR , typename NumericT > | |
| void | async_copy (const CPUVECTOR &cpu_vec, vector_base< NumericT > &gpu_vec) |
| Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());. More... | |
| template<typename NumericT , unsigned int AlignmentV, typename CPU_ITERATOR > | |
| void | copy (CPU_ITERATOR const &cpu_begin, CPU_ITERATOR const &cpu_end, vector_iterator< NumericT, AlignmentV > gpu_begin) |
| STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory. More... | |
| template<typename HostVectorT , typename T > | |
| void | copy (HostVectorT const &cpu_vec, vector_base< T > &gpu_vec) |
| Transfer from a host vector object to a ViennaCL vector proxy. Requires the vector proxy to have the necessary size. Convenience wrapper for viennacl::linalg::copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());. More... | |
| template<typename HostVectorT , typename T , unsigned int AlignmentV> | |
| void | copy (HostVectorT const &cpu_vec, vector< T, AlignmentV > &gpu_vec) |
| Transfer from a host vector object to a ViennaCL vector. Resizes the ViennaCL vector if it has zero size. Convenience wrapper for viennacl::linalg::copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());. More... | |
| template<typename NumericT , unsigned int AlignmentV_SRC, unsigned int AlignmentV_DEST> | |
| void | copy (const_vector_iterator< NumericT, AlignmentV_SRC > const &gpu_src_begin, const_vector_iterator< NumericT, AlignmentV_SRC > const &gpu_src_end, vector_iterator< NumericT, AlignmentV_DEST > gpu_dest_begin) |
| Copy (parts of a) GPU vector to another GPU vector. More... | |
| template<typename NumericT , unsigned int AlignmentV_SRC, unsigned int AlignmentV_DEST> | |
| void | copy (vector_iterator< NumericT, AlignmentV_SRC > const &gpu_src_begin, vector_iterator< NumericT, AlignmentV_SRC > const &gpu_src_end, vector_iterator< NumericT, AlignmentV_DEST > gpu_dest_begin) |
| Copy (parts of a) GPU vector to another GPU vector. More... | |
| template<typename NumericT , unsigned int AlignmentV_SRC, unsigned int AlignmentV_DEST> | |
| void | copy (vector< NumericT, AlignmentV_SRC > const &gpu_src_vec, vector< NumericT, AlignmentV_DEST > &gpu_dest_vec) |
| Transfer from a ViennaCL vector to another ViennaCL vector. Convenience wrapper for viennacl::linalg::copy(gpu_src_vec.begin(), gpu_src_vec.end(), gpu_dest_vec.begin());. More... | |
| template<typename T > | |
| std::ostream & | operator<< (std::ostream &os, vector_base< T > const &val) |
| Output stream. Output format is ublas compatible. More... | |
| template<typename LHS , typename RHS , typename OP > | |
| std::ostream & | operator<< (std::ostream &os, vector_expression< LHS, RHS, OP > const &proxy) |
| template<typename T > | |
| void | swap (vector_base< T > &vec1, vector_base< T > &vec2) |
| Swaps the contents of two vectors, data is copied. More... | |
| template<typename NumericT , unsigned int AlignmentV> | |
| vector< NumericT, AlignmentV > & | fast_swap (vector< NumericT, AlignmentV > &v1, vector< NumericT, AlignmentV > &v2) |
| Swaps the content of two vectors by swapping OpenCL handles only, NO data is copied. More... | |
| template<typename T , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, vector_base< T > & >::type | operator*= (vector_base< T > &v1, S1 const &gpu_val) |
| Scales this vector by a GPU scalar value. More... | |
| template<typename T , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, vector_base< T > & >::type | operator/= (vector_base< T > &v1, S1 const &gpu_val) |
| Scales this vector by a GPU scalar value. More... | |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename LHS2 , typename RHS2 , typename OP2 > | |
| vector_expression< const vector_expression< LHS1, RHS1, OP1 >, const vector_expression < LHS2, RHS2, OP2 > , viennacl::op_add > | operator+ (vector_expression< LHS1, RHS1, OP1 > const &proxy1, vector_expression< LHS2, RHS2, OP2 > const &proxy2) |
| Operator overload for the addition of two vector expressions. More... | |
| template<typename LHS , typename RHS , typename OP , typename T > | |
| vector_expression< const vector_expression< LHS, RHS, OP >, const vector_base< T > , viennacl::op_add > | operator+ (vector_expression< LHS, RHS, OP > const &proxy, vector_base< T > const &vec) |
| Operator overload for the addition of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created. More... | |
| template<typename T , typename LHS , typename RHS , typename OP > | |
| vector_expression< const vector_base< T >, const vector_expression< LHS, RHS, OP >, viennacl::op_add > | operator+ (vector_base< T > const &vec, vector_expression< LHS, RHS, OP > const &proxy) |
| Operator overload for the addition of a vector with a vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const vector_base< T >, op_add > | operator+ (const vector_base< T > &v1, const vector_base< T > &v2) |
| Returns an expression template object for adding up two vectors, i.e. v1 + v2. More... | |
| template<typename LHS1 , typename RHS1 , typename OP1 , typename LHS2 , typename RHS2 , typename OP2 > | |
| vector_expression< const vector_expression< LHS1, RHS1, OP1 >, const vector_expression < LHS2, RHS2, OP2 > , viennacl::op_sub > | operator- (vector_expression< LHS1, RHS1, OP1 > const &proxy1, vector_expression< LHS2, RHS2, OP2 > const &proxy2) |
| Operator overload for the subtraction of two vector expressions. More... | |
| template<typename LHS , typename RHS , typename OP , typename T > | |
| vector_expression< const vector_expression< LHS, RHS, OP >, const vector_base< T > , viennacl::op_sub > | operator- (vector_expression< LHS, RHS, OP > const &proxy, vector_base< T > const &vec) |
| Operator overload for the subtraction of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created. More... | |
| template<typename T , typename LHS , typename RHS , typename OP > | |
| vector_expression< const vector_base< T >, const vector_expression< LHS, RHS, OP >, viennacl::op_sub > | operator- (vector_base< T > const &vec, vector_expression< LHS, RHS, OP > const &proxy) |
| Operator overload for the subtraction of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const vector_base< T >, op_sub > | operator- (const vector_base< T > &v1, const vector_base< T > &v2) |
| Returns an expression template object for subtracting two vectors, i.e. v1 - v2. More... | |
| template<typename S1 , typename T > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, vector_expression < const vector_base< T > , const S1, op_mult > >::type | operator* (S1 const &value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a host scalar (float or double) and v1 is a ViennaCL vector. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (char value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a char. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (short value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a short. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (int value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a int. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (long value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a long. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (float value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a float. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (double value, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a double. More... | |
| template<typename LHS , typename RHS , typename OP , typename T > | |
| vector_expression< const vector_base< T >, const scalar_expression< LHS, RHS, OP >, op_mult > | operator* (scalar_expression< LHS, RHS, OP > const &expr, vector_base< T > const &vec) |
| Operator overload for the expression alpha * v1, where alpha is a scalar expression and v1 is a ViennaCL vector. More... | |
| template<typename T , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, vector_expression < const vector_base< T > , const S1, op_mult > >::type | operator* (vector_base< T > const &vec, S1 const &value) |
| Scales the vector by a scalar 'alpha' and returns an expression template. More... | |
| template<typename T > | |
| vector_expression< const vector_base< T >, const T, op_mult > | operator* (vector_base< T > const &vec, T const &value) |
| template<typename LHS , typename RHS , typename OP , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, viennacl::vector_expression < const vector_expression< LHS, RHS, OP >, const S1, op_mult > >::type | operator* (vector_expression< LHS, RHS, OP > const &proxy, S1 const &val) |
| Operator overload for the multiplication of a vector expression with a scalar from the right, e.g. (beta * vec1) * alpha. Here, beta * vec1 is wrapped into a vector_expression and then multiplied with alpha from the right. More... | |
| template<typename S1 , typename LHS , typename RHS , typename OP > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, viennacl::vector_expression < const vector_expression< LHS, RHS, OP >, const S1, op_mult > >::type | operator* (S1 const &val, vector_expression< LHS, RHS, OP > const &proxy) |
| Operator overload for the multiplication of a vector expression with a ViennaCL scalar from the left, e.g. alpha * (beta * vec1). Here, beta * vec1 is wrapped into a vector_expression and then multiplied with alpha from the left. More... | |
| template<typename S1 , typename LHS , typename RHS , typename OP > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, viennacl::vector_expression < const vector_expression< LHS, RHS, OP >, const S1, op_div > >::type | operator/ (vector_expression< LHS, RHS, OP > const &proxy, S1 const &val) |
| Operator overload for the division of a vector expression by a scalar from the right, e.g. (beta * vec1) / alpha. Here, beta * vec1 is wrapped into a vector_expression and then divided by alpha. More... | |
| template<typename T , typename S1 > | |
| viennacl::enable_if < viennacl::is_any_scalar< S1 > ::value, vector_expression < const vector_base< T > , const S1, op_div > >::type | operator/ (vector_base< T > const &v1, S1 const &s1) |
| Returns an expression template for scaling the vector by a GPU scalar 'alpha'. More... | |
| template<typename VectorType , typename NumericT > | |
| void | copy (const VectorType &cpu_vector, vector_range< vector< NumericT > > &gpu_vector_range) |
| template<typename CPUVECTOR , typename VectorType > | |
| void | fast_copy (const CPUVECTOR &cpu_vec, vector_range< VectorType > &gpu_vec) |
| Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());. More... | |
| template<typename NumericT , typename VectorType > | |
| void | copy (vector_range< vector< NumericT > > const &gpu_vector_range, VectorType &cpu_vector) |
| template<typename VectorType , typename CPUVECTOR > | |
| void | fast_copy (vector_range< VectorType > const &gpu_vec, CPUVECTOR &cpu_vec) |
| Transfer from a GPU vector range to a CPU vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());. More... | |
| template<typename VectorType > | |
| vector_range< VectorType > | project (VectorType const &vec, viennacl::range const &r1) |
| template<typename VectorType > | |
| vector_range< VectorType > | project (viennacl::vector_range< VectorType > const &vec, viennacl::range const &r1) |
| template<typename VectorType , typename NumericT > | |
| void | copy (const VectorType &cpu_vector, vector_slice< vector< NumericT > > &gpu_vector_slice) |
| template<typename VectorType , typename NumericT > | |
| void | copy (vector_slice< vector< NumericT > > const &gpu_vector_slice, VectorType &cpu_vector) |
| template<typename VectorType > | |
| vector_slice< VectorType > | project (VectorType const &vec, viennacl::slice const &s1) |
| template<typename VectorType > | |
| vector_slice< VectorType > | project (viennacl::vector_slice< VectorType > const &vec, viennacl::slice const &s1) |
| template<typename VectorType > | |
| vector_slice< VectorType > | project (viennacl::vector_slice< VectorType > const &vec, viennacl::range const &r1) |
| template<typename VectorType > | |
| vector_slice< VectorType > | project (viennacl::vector_range< VectorType > const &vec, viennacl::slice const &s1) |
Main namespace in ViennaCL. Holds all the basic types such as vector, matrix, etc. and defines operations upon them.
| typedef basic_range viennacl::range |
Definition at line 424 of file forwards.h.
| typedef basic_slice viennacl::slice |
Definition at line 429 of file forwards.h.
| typedef std::ptrdiff_t viennacl::vcl_ptrdiff_t |
Definition at line 76 of file forwards.h.
| typedef std::size_t viennacl::vcl_size_t |
Definition at line 75 of file forwards.h.
| Enumerator | |
|---|---|
| MEMORY_NOT_INITIALIZED | |
| MAIN_MEMORY | |
| OPENCL_MEMORY | |
| CUDA_MEMORY | |
Definition at line 345 of file forwards.h.
| void viennacl::async_copy | ( | const const_vector_iterator< NumericT, AlignmentV > & | gpu_begin, |
| const const_vector_iterator< NumericT, AlignmentV > & | gpu_end, | ||
| CPU_ITERATOR | cpu_begin | ||
| ) |
Asynchronous version of fast_copy(), copying data from device to host. The host iterator cpu_begin needs to reside in a linear piece of memory, such as e.g. for std::vector.
This method allows for overlapping data transfer with host computation and returns immediately if the gpu vector has a unit-stride. In order to wait for the transfer to complete, use viennacl::backend::finish(). Note that data pointed to by cpu_begin must not be modified prior to completion of the transfer.
| gpu_begin | GPU iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_end | GPU iterator pointing to the end of the vector (STL-like) |
| cpu_begin | Output iterator for the cpu vector. The cpu vector must be at least as long as the gpu vector! |
Definition at line 1284 of file vector.hpp.
| void viennacl::async_copy | ( | vector_base< NumericT > const & | gpu_vec, |
| CPUVECTOR & | cpu_vec | ||
| ) |
Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());.
| gpu_vec | A gpu vector. |
| cpu_vec | The cpu vector. Type requirements: Output iterator pointing to entries linear in memory can be obtained via member function .begin() |
Definition at line 1309 of file vector.hpp.
| void viennacl::async_copy | ( | CPU_ITERATOR const & | cpu_begin, |
| CPU_ITERATOR const & | cpu_end, | ||
| vector_iterator< NumericT, AlignmentV > | gpu_begin | ||
| ) |
Asynchronous version of fast_copy(), copying data from host to device. The host iterator cpu_begin needs to reside in a linear piece of memory, such as e.g. for std::vector.
This method allows for overlapping data transfer with host computation and returns immediately if the gpu vector has a unit-stride. In order to wait for the transfer to complete, use viennacl::backend::finish(). Note that data pointed to by cpu_begin must not be modified prior to completion of the transfer.
| cpu_begin | CPU iterator pointing to the beginning of the cpu vector (STL-like) |
| cpu_end | CPU iterator pointing to the end of the vector (STL-like) |
| gpu_begin | Output iterator for the gpu vector. The gpu iterator must be incrementable (cpu_end - cpu_begin) times, otherwise the result is undefined. |
Definition at line 1450 of file vector.hpp.
| void viennacl::async_copy | ( | const CPUVECTOR & | cpu_vec, |
| vector_base< NumericT > & | gpu_vec | ||
| ) |
Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());.
| cpu_vec | A cpu vector. Type requirements: Iterator can be obtained via member function .begin() and .end() |
| gpu_vec | The gpu vector. |
Definition at line 1475 of file vector.hpp.
| vector_expression< const matrix_base<NumericT, F>, const unsigned int, op_column> viennacl::column | ( | const matrix_base< NumericT, F > & | A, |
| unsigned int | j | ||
| ) |
Definition at line 918 of file matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| coordinate_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU)
For the requirements on the CPUMatrixT type, see the documentation of the function copy(CPUMatrixT, compressed_matrix<>)
| cpu_matrix | A sparse matrix on the host. |
| gpu_matrix | A compressed_matrix from ViennaCL |
Definition at line 47 of file coordinate_matrix.hpp.
| void viennacl::copy | ( | const VectorType & | cpu_vector, |
| vector_range< vector< NumericT > > & | gpu_vector_range | ||
| ) |
Definition at line 103 of file vector_proxy.hpp.
| void viennacl::copy | ( | const std::vector< std::map< unsigned int, NumericT > > & | cpu_matrix, |
| coordinate_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse matrix in the std::vector< std::map < > > format to an OpenCL device.
| cpu_matrix | A sparse square matrix on the host. |
| gpu_matrix | A coordinate_matrix from ViennaCL |
Definition at line 110 of file coordinate_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| compressed_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU)
There are some type requirements on the CPUMatrixT type (fulfilled by e.g. boost::numeric::ublas):
| cpu_matrix | A sparse matrix on the host. |
| gpu_matrix | A compressed_matrix from ViennaCL |
Definition at line 112 of file compressed_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| compressed_compressed_matrix< NumericT > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the OpenCL device (either GPU or multi-core CPU)
There are some type requirements on the CPUMatrixT type (fulfilled by e.g. boost::numeric::ublas):
| cpu_matrix | A sparse matrix on the host. |
| gpu_matrix | A compressed_compressed_matrix from ViennaCL |
Definition at line 115 of file compressed_compressed_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| ell_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Definition at line 124 of file ell_matrix.hpp.
| void viennacl::copy | ( | const coordinate_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host.
There are two type requirements on the CPUMatrixT type (fulfilled by e.g. boost::numeric::ublas):
| gpu_matrix | A coordinate_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 134 of file coordinate_matrix.hpp.
| void viennacl::copy | ( | vector_range< vector< NumericT > > const & | gpu_vector_range, |
| VectorType & | cpu_vector | ||
| ) |
Definition at line 135 of file vector_proxy.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| hyb_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Definition at line 136 of file hyb_matrix.hpp.
| void viennacl::copy | ( | CPUMatrixT const & | cpu_matrix, |
| sliced_ell_matrix< ScalarT, IndexT > & | gpu_matrix | ||
| ) |
Definition at line 141 of file sliced_ell_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| matrix_range< matrix< NumericT, row_major, 1 > > & | gpu_matrix_range | ||
| ) |
Definition at line 147 of file matrix_proxy.hpp.
| void viennacl::copy | ( | std::vector< NumericT > & | cpu_vec, |
| vandermonde_matrix< NumericT, AlignmentV > & | gpu_mat | ||
| ) |
Copies a Vandermonde matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU)
| cpu_vec | A std::vector on the host. |
| gpu_mat | A vandermonde_matrix from ViennaCL |
Definition at line 148 of file vandermonde_matrix.hpp.
| void viennacl::copy | ( | std::vector< NumericT > const & | cpu_vec, |
| hankel_matrix< NumericT, AlignmentV > & | gpu_mat | ||
| ) |
Copies a Hankel matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU)
| cpu_vec | A std::vector on the host. |
| gpu_mat | A hankel_matrix from ViennaCL |
Definition at line 148 of file hankel_matrix.hpp.
| void viennacl::copy | ( | const std::vector< std::map< SizeT, NumericT > > & | cpu_matrix, |
| compressed_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse square matrix in the std::vector< std::map < > > format to an OpenCL device. Use viennacl::tools::sparse_matrix_adapter for non-square matrices.
| cpu_matrix | A sparse square matrix on the host using STL types |
| gpu_matrix | A compressed_matrix from ViennaCL |
Definition at line 149 of file compressed_matrix.hpp.
| void viennacl::copy | ( | std::vector< NumericT > & | cpu_vec, |
| circulant_matrix< NumericT, AlignmentV > & | gpu_mat | ||
| ) |
Copies a circulant matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU)
| cpu_vec | A std::vector on the host. |
| gpu_mat | A circulant_matrix from ViennaCL |
Definition at line 150 of file circulant_matrix.hpp.
| void viennacl::copy | ( | std::vector< NumericT > const & | cpu_vec, |
| toeplitz_matrix< NumericT, AlignmentV > & | gpu_mat | ||
| ) |
Copies a Toeplitz matrix from the std::vector to the OpenCL device (either GPU or multi-core CPU)
| cpu_vec | A std::vector on the host. |
| gpu_mat | A toeplitz_matrix from ViennaCL |
Definition at line 158 of file toeplitz_matrix.hpp.
| void viennacl::copy | ( | vandermonde_matrix< NumericT, AlignmentV > & | gpu_mat, |
| std::vector< NumericT > & | cpu_vec | ||
| ) |
Copies a Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector.
| gpu_mat | A vandermonde_matrix from ViennaCL |
| cpu_vec | A std::vector on the host. |
Definition at line 161 of file vandermonde_matrix.hpp.
| void viennacl::copy | ( | hankel_matrix< NumericT, AlignmentV > const & | gpu_mat, |
| std::vector< NumericT > & | cpu_vec | ||
| ) |
Copies a Hankel matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector.
| gpu_mat | A hankel_matrix from ViennaCL |
| cpu_vec | A std::vector on the host. |
Definition at line 162 of file hankel_matrix.hpp.
| void viennacl::copy | ( | circulant_matrix< NumericT, AlignmentV > & | gpu_mat, |
| std::vector< NumericT > & | cpu_vec | ||
| ) |
Copies a circulant matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector.
| gpu_mat | A circulant_matrix from ViennaCL |
| cpu_vec | A std::vector on the host. |
Definition at line 163 of file circulant_matrix.hpp.
| void viennacl::copy | ( | const coordinate_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| std::vector< std::map< unsigned int, NumericT > > & | cpu_matrix | ||
| ) |
Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format .
| gpu_matrix | A coordinate_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 164 of file coordinate_matrix.hpp.
| void viennacl::copy | ( | const std::vector< std::map< SizeT, NumericT > > & | cpu_matrix, |
| compressed_compressed_matrix< NumericT > & | gpu_matrix | ||
| ) |
Copies a sparse square matrix in the std::vector< std::map < > > format to an OpenCL device. Use viennacl::tools::sparse_matrix_adapter for non-square matrices.
| cpu_matrix | A sparse square matrix on the host using STL types |
| gpu_matrix | A compressed_compressed_matrix from ViennaCL |
Definition at line 164 of file compressed_compressed_matrix.hpp.
| void viennacl::copy | ( | vandermonde_matrix< NumericT, AlignmentV > & | vander_src, |
| MatrixT & | com_dst | ||
| ) |
Copies a Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object.
| vander_src | A vandermonde_matrix from ViennaCL |
| com_dst | A matrix-like object |
Definition at line 174 of file vandermonde_matrix.hpp.
| void viennacl::copy | ( | circulant_matrix< NumericT, AlignmentV > & | circ_src, |
| MatrixT & | com_dst | ||
| ) |
Copies a circulant matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object.
| circ_src | A circulant_matrix from ViennaCL |
| com_dst | A matrix-like object |
Definition at line 176 of file circulant_matrix.hpp.
| void viennacl::copy | ( | hankel_matrix< NumericT, AlignmentV > const & | han_src, |
| MatrixT & | com_dst | ||
| ) |
Copies a Hankel matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object.
| han_src | A hankel_matrix from ViennaCL |
| com_dst | A matrix-like object |
Definition at line 176 of file hankel_matrix.hpp.
| void viennacl::copy | ( | std::vector< std::map< IndexT, NumericT > > const & | cpu_matrix, |
| ell_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format .
| cpu_matrix | A sparse matrix on the host composed of an STL vector and an STL map. |
| gpu_matrix | The sparse ell_matrix from ViennaCL |
Definition at line 181 of file ell_matrix.hpp.
| void viennacl::copy | ( | toeplitz_matrix< NumericT, AlignmentV > const & | gpu_mat, |
| std::vector< NumericT > & | cpu_vec | ||
| ) |
Copies a Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU) to the std::vector.
| gpu_mat | A toeplitz_matrix from ViennaCL |
| cpu_vec | A std::vector on the host. |
Definition at line 182 of file toeplitz_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| matrix_range< matrix< NumericT, column_major, 1 > > & | gpu_matrix_range | ||
| ) |
Definition at line 189 of file matrix_proxy.hpp.
| void viennacl::copy | ( | MatrixT & | com_src, |
| vandermonde_matrix< NumericT, AlignmentV > & | vander_dst | ||
| ) |
Copies a the matrix-like object to the Vandermonde matrix from the OpenCL device (either GPU or multi-core CPU)
| com_src | A std::vector on the host |
| vander_dst | A vandermonde_matrix from ViennaCL |
Definition at line 196 of file vandermonde_matrix.hpp.
| void viennacl::copy | ( | MatrixT const & | com_src, |
| hankel_matrix< NumericT, AlignmentV > & | han_dst | ||
| ) |
Copies a the matrix-like object to the Hankel matrix from the OpenCL device (either GPU or multi-core CPU)
| com_src | A std::vector on the host |
| han_dst | A hankel_matrix from ViennaCL |
Definition at line 197 of file hankel_matrix.hpp.
| void viennacl::copy | ( | const compressed_compressed_matrix< NumericT > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host.
There are two type requirements on the CPUMatrixT type (fulfilled by e.g. boost::numeric::ublas):
| gpu_matrix | A compressed_compressed_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 199 of file compressed_compressed_matrix.hpp.
| void viennacl::copy | ( | const ell_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 200 of file ell_matrix.hpp.
| void viennacl::copy | ( | MatrixT & | com_src, |
| circulant_matrix< NumericT, AlignmentV > & | circ_dst | ||
| ) |
Copies a the matrix-like object to the circulant matrix from the OpenCL device (either GPU or multi-core CPU)
| com_src | A std::vector on the host |
| circ_dst | A circulant_matrix from ViennaCL |
Definition at line 203 of file circulant_matrix.hpp.
| void viennacl::copy | ( | toeplitz_matrix< NumericT, AlignmentV > const & | tep_src, |
| MatrixT & | com_dst | ||
| ) |
Copies a Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU) to the matrix-like object.
| tep_src | A toeplitz_matrix from ViennaCL |
| com_dst | A matrix-like object |
Definition at line 204 of file toeplitz_matrix.hpp.
| void viennacl::copy | ( | std::vector< std::map< IndexT, NumericT > > const & | cpu_matrix, |
| sliced_ell_matrix< NumericT, IndexT2 > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format .
| cpu_matrix | A sparse matrix on the host composed of an STL vector and an STL map. |
| gpu_matrix | The sparse ell_matrix from ViennaCL |
Definition at line 224 of file sliced_ell_matrix.hpp.
| void viennacl::copy | ( | MatrixT const & | com_src, |
| toeplitz_matrix< NumericT, AlignmentV > & | tep_dst | ||
| ) |
Copies a the matrix-like object to the Toeplitz matrix from the OpenCL device (either GPU or multi-core CPU)
| com_src | A std::vector on the host |
| tep_dst | A toeplitz_matrix from ViennaCL |
Definition at line 225 of file toeplitz_matrix.hpp.
| void viennacl::copy | ( | matrix_range< matrix< NumericT, row_major, 1 > > const & | gpu_matrix_range, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 238 of file matrix_proxy.hpp.
| void viennacl::copy | ( | const ell_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| std::vector< std::map< IndexT, NumericT > > & | cpu_matrix | ||
| ) |
Copies a sparse matrix from the compute device to the host. The host type is the std::vector< std::map < > > format .
| gpu_matrix | The sparse ell_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host composed of an STL vector and an STL map. |
Definition at line 242 of file ell_matrix.hpp.
| void viennacl::copy | ( | std::vector< std::map< IndexT, NumericT > > const & | cpu_matrix, |
| hyb_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a sparse matrix from the host to the compute device. The host type is the std::vector< std::map < > > format .
| cpu_matrix | A sparse matrix on the host composed of an STL vector and an STL map. |
| gpu_matrix | The sparse hyb_matrix from ViennaCL |
Definition at line 243 of file hyb_matrix.hpp.
| void viennacl::copy | ( | const compressed_compressed_matrix< NumericT > & | gpu_matrix, |
| std::vector< std::map< unsigned int, NumericT > > & | cpu_matrix | ||
| ) |
Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format .
| gpu_matrix | A compressed_compressed_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 248 of file compressed_compressed_matrix.hpp.
| void viennacl::copy | ( | const hyb_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 260 of file hyb_matrix.hpp.
| void viennacl::copy | ( | const VectorType & | cpu_vector, |
| vector_slice< vector< NumericT > > & | gpu_vector_slice | ||
| ) |
Definition at line 261 of file vector_proxy.hpp.
| void viennacl::copy | ( | CPU_ITERATOR const & | cpu_begin, |
| CPU_ITERATOR const & | cpu_end, | ||
| vector_iterator< SCALARTYPE, ALIGNMENT > | gpu_begin | ||
| ) |
| void viennacl::copy | ( | const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const & | gpu_src_begin, |
| const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const & | gpu_src_end, | ||
| vector_iterator< SCALARTYPE, ALIGNMENT_DEST > | gpu_dest_begin | ||
| ) |
| void viennacl::copy | ( | matrix_range< matrix< NumericT, column_major, 1 > > const & | gpu_matrix_range, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 280 of file matrix_proxy.hpp.
| void viennacl::copy | ( | const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const & | gpu_src_begin, |
| const_vector_iterator< SCALARTYPE, ALIGNMENT_SRC > const & | gpu_src_end, | ||
| const_vector_iterator< SCALARTYPE, ALIGNMENT_DEST > | gpu_dest_begin | ||
| ) |
| void viennacl::copy | ( | vector_slice< vector< NumericT > > const & | gpu_vector_slice, |
| VectorType & | cpu_vector | ||
| ) |
Definition at line 285 of file vector_proxy.hpp.
| void viennacl::copy | ( | const hyb_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| std::vector< std::map< IndexT, NumericT > > & | cpu_matrix | ||
| ) |
Copies a sparse matrix from the compute device to the host. The host type is the std::vector< std::map < > > format .
| gpu_matrix | The sparse hyb_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host composed of an STL vector and an STL map. |
Definition at line 324 of file hyb_matrix.hpp.
| void viennacl::copy | ( | const compressed_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Copies a sparse matrix from the OpenCL device (either GPU or multi-core CPU) to the host.
There are two type requirements on the CPUMatrixT type (fulfilled by e.g. boost::numeric::ublas):
| gpu_matrix | A compressed_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 341 of file compressed_matrix.hpp.
| void viennacl::copy | ( | const compressed_matrix< NumericT, AlignmentV > & | gpu_matrix, |
| std::vector< std::map< unsigned int, NumericT > > & | cpu_matrix | ||
| ) |
Copies a sparse matrix from an OpenCL device to the host. The host type is the std::vector< std::map < > > format .
| gpu_matrix | A compressed_matrix from ViennaCL |
| cpu_matrix | A sparse matrix on the host. |
Definition at line 387 of file compressed_matrix.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| matrix_slice< matrix< NumericT, row_major, 1 > > & | gpu_matrix_slice | ||
| ) |
Definition at line 439 of file matrix_proxy.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| matrix_slice< matrix< NumericT, column_major, 1 > > & | gpu_matrix_slice | ||
| ) |
Definition at line 468 of file matrix_proxy.hpp.
| void viennacl::copy | ( | matrix_slice< matrix< NumericT, row_major, 1 > > const & | gpu_matrix_slice, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 506 of file matrix_proxy.hpp.
| void viennacl::copy | ( | matrix_slice< matrix< NumericT, column_major, 1 > > const & | gpu_matrix_slice, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Definition at line 536 of file matrix_proxy.hpp.
| void viennacl::copy | ( | const CPUMatrixT & | cpu_matrix, |
| matrix< NumericT, F, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a dense matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU)
| cpu_matrix | A dense matrix on the host. Type requirements: .size1() returns number of rows, .size2() returns number of columns. Access to entries via operator() |
| gpu_matrix | A dense ViennaCL matrix |
Definition at line 934 of file matrix.hpp.
| void viennacl::copy | ( | const std::vector< std::vector< NumericT, A1 >, A2 > & | cpu_matrix, |
| matrix< NumericT, F, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a dense STL-type matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU)
| cpu_matrix | A dense matrix on the host of type std::vector< std::vector<> >. cpu_matrix[i][j] returns the element in the i-th row and j-th columns (both starting with zero) |
| gpu_matrix | A dense ViennaCL matrix |
Definition at line 970 of file matrix.hpp.
| void viennacl::copy | ( | const matrix< NumericT, F, AlignmentV > & | gpu_matrix, |
| CPUMatrixT & | cpu_matrix | ||
| ) |
Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU).
| gpu_matrix | A dense ViennaCL matrix |
| cpu_matrix | A dense memory on the host. Must have at least as many rows and columns as the gpu_matrix! Type requirement: Access to entries via operator() |
Definition at line 1170 of file matrix.hpp.
| void viennacl::copy | ( | const matrix< NumericT, F, AlignmentV > & | gpu_matrix, |
| std::vector< std::vector< NumericT, A1 >, A2 > & | cpu_matrix | ||
| ) |
Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU).
| gpu_matrix | A dense ViennaCL matrix |
| cpu_matrix | A dense memory on the host using STL types, typically std::vector< std::vector<> > Must have at least as many rows and columns as the gpu_matrix! Type requirement: Access to entries via operator() |
Definition at line 1199 of file matrix.hpp.
| void viennacl::copy | ( | const const_vector_iterator< NumericT, AlignmentV > & | gpu_begin, |
| const const_vector_iterator< NumericT, AlignmentV > & | gpu_end, | ||
| CPU_ITERATOR | cpu_begin | ||
| ) |
STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory.
| gpu_begin | GPU constant iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_end | GPU constant iterator pointing to the end of the vector (STL-like) |
| cpu_begin | Output iterator for the cpu vector. The cpu vector must be at least as long as the gpu vector! |
Definition at line 1322 of file vector.hpp.
| void viennacl::copy | ( | const vector_iterator< NumericT, AlignmentV > & | gpu_begin, |
| const vector_iterator< NumericT, AlignmentV > & | gpu_end, | ||
| CPU_ITERATOR | cpu_begin | ||
| ) |
STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory.
| gpu_begin | GPU iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_end | GPU iterator pointing to the end of the vector (STL-like) |
| cpu_begin | Output iterator for the cpu vector. The cpu vector must be at least as long as the gpu vector! |
Definition at line 1344 of file vector.hpp.
| void viennacl::copy | ( | vector_base< NumericT > const & | gpu_vec, |
| CPUVECTOR & | cpu_vec | ||
| ) |
Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());.
| gpu_vec | A gpu vector |
| cpu_vec | The cpu vector. Type requirements: Output iterator can be obtained via member function .begin() |
Definition at line 1360 of file vector.hpp.
| void viennacl::copy | ( | CPU_ITERATOR const & | cpu_begin, |
| CPU_ITERATOR const & | cpu_end, | ||
| vector_iterator< NumericT, AlignmentV > | gpu_begin | ||
| ) |
STL-like transfer for the entries of a GPU vector to the CPU. The cpu type does not need to lie in a linear piece of memory.
| cpu_begin | CPU iterator pointing to the beginning of the gpu vector (STL-like) |
| cpu_end | CPU iterator pointing to the end of the vector (STL-like) |
| gpu_begin | Output iterator for the gpu vector. The gpu vector must be at least as long as the cpu vector! |
Definition at line 1488 of file vector.hpp.
| void viennacl::copy | ( | HostVectorT const & | cpu_vec, |
| vector_base< T > & | gpu_vec | ||
| ) |
Transfer from a host vector object to a ViennaCL vector proxy. Requires the vector proxy to have the necessary size. Convenience wrapper for viennacl::linalg::copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());.
| cpu_vec | A cpu vector. Type requirements: Iterator can be obtained via member function .begin() and .end() |
| gpu_vec | The gpu vector. |
Definition at line 1510 of file vector.hpp.
| void viennacl::copy | ( | HostVectorT const & | cpu_vec, |
| vector< T, AlignmentV > & | gpu_vec | ||
| ) |
Transfer from a host vector object to a ViennaCL vector. Resizes the ViennaCL vector if it has zero size. Convenience wrapper for viennacl::linalg::copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());.
| cpu_vec | A host vector. Type requirements: Iterator can be obtained via member function .begin() and .end() |
| gpu_vec | The gpu (ViennaCL) vector. |
Definition at line 1521 of file vector.hpp.
| void viennacl::copy | ( | const_vector_iterator< NumericT, AlignmentV_SRC > const & | gpu_src_begin, |
| const_vector_iterator< NumericT, AlignmentV_SRC > const & | gpu_src_end, | ||
| vector_iterator< NumericT, AlignmentV_DEST > | gpu_dest_begin | ||
| ) |
Copy (parts of a) GPU vector to another GPU vector.
| gpu_src_begin | GPU iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_src_end | GPU iterator pointing to the end of the vector (STL-like) |
| gpu_dest_begin | Output iterator for the gpu vector. The gpu_dest vector must be at least as long as the gpu_src vector! |
Definition at line 1557 of file vector.hpp.
| void viennacl::copy | ( | vector_iterator< NumericT, AlignmentV_SRC > const & | gpu_src_begin, |
| vector_iterator< NumericT, AlignmentV_SRC > const & | gpu_src_end, | ||
| vector_iterator< NumericT, AlignmentV_DEST > | gpu_dest_begin | ||
| ) |
Copy (parts of a) GPU vector to another GPU vector.
| gpu_src_begin | GPU iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_src_end | GPU iterator pointing to the end of the vector (STL-like) |
| gpu_dest_begin | Output iterator for the gpu vector. The gpu vector must be at least as long as the cpu vector! |
Definition at line 1585 of file vector.hpp.
| void viennacl::copy | ( | vector< NumericT, AlignmentV_SRC > const & | gpu_src_vec, |
| vector< NumericT, AlignmentV_DEST > & | gpu_dest_vec | ||
| ) |
Transfer from a ViennaCL vector to another ViennaCL vector. Convenience wrapper for viennacl::linalg::copy(gpu_src_vec.begin(), gpu_src_vec.end(), gpu_dest_vec.begin());.
| gpu_src_vec | A gpu vector |
| gpu_dest_vec | The cpu vector. Type requirements: Output iterator can be obtained via member function .begin() |
Definition at line 1600 of file vector.hpp.
Convenience helper function for extracting the CUDA handle from a ViennaCL scalar. Non-const version.
Definition at line 39 of file common.hpp.
Convenience helper function for extracting the CUDA handle from a ViennaCL scalar. Const version.
Definition at line 46 of file common.hpp.
Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base) with implicit return type deduction. Non-const version.
Definition at line 56 of file common.hpp.
| const NumericT* viennacl::cuda_arg | ( | vector_base< NumericT > const & | obj | ) |
Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base) with implicit return type deduction. Const version.
Definition at line 63 of file common.hpp.
| ReturnT* viennacl::cuda_arg | ( | vector_base< NumericT > & | obj | ) |
Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base). Return type needs to be explicitly provided as first template argument. Non-const version.
Definition at line 70 of file common.hpp.
| const ReturnT* viennacl::cuda_arg | ( | vector_base< NumericT > const & | obj | ) |
Convenience helper function for extracting the CUDA handle from a ViennaCL vector (through the base class vector_base). Return type needs to be explicitly provided as first template argument. Const version.
Definition at line 77 of file common.hpp.
Convenience helper function for extracting the CUDA handle from a ViennaCL matrix (through the base class matrix_base). Non-const version.
Definition at line 87 of file common.hpp.
| const NumericT* viennacl::cuda_arg | ( | matrix_base< NumericT > const & | obj | ) |
Convenience helper function for extracting the CUDA handle from a ViennaCL matrix (through the base class matrix_base). Const version.
Definition at line 94 of file common.hpp.
| ReturnT* viennacl::cuda_arg | ( | viennacl::backend::mem_handle & | h | ) |
Convenience helper function for extracting the CUDA handle from a generic memory handle. Non-const version.
Definition at line 106 of file common.hpp.
| ReturnT const* viennacl::cuda_arg | ( | viennacl::backend::mem_handle const & | h | ) |
Convenience helper function for extracting the CUDA handle from a generic memory handle. Const-version.
Definition at line 113 of file common.hpp.
| vector_expression< const matrix_base<NumericT>, const int, op_matrix_diag> viennacl::diag | ( | const matrix_base< NumericT > & | A, |
| int | k = 0 |
||
| ) |
Definition at line 895 of file matrix.hpp.
| matrix_expression< const vector_base<NumericT>, const int, op_vector_diag> viennacl::diag | ( | const vector_base< NumericT > & | v, |
| int | k = 0 |
||
| ) |
Definition at line 902 of file matrix.hpp.
| void viennacl::fast_copy | ( | const CPUVECTOR & | cpu_vec, |
| vector_range< VectorType > & | gpu_vec | ||
| ) |
Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());.
| cpu_vec | A cpu vector. Type requirements: Iterator can be obtained via member function .begin() and .end() |
| gpu_vec | The gpu vector. |
Definition at line 124 of file vector_proxy.hpp.
| void viennacl::fast_copy | ( | vector_range< VectorType > const & | gpu_vec, |
| CPUVECTOR & | cpu_vec | ||
| ) |
Transfer from a GPU vector range to a CPU vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());.
| gpu_vec | A gpu vector range. |
| cpu_vec | The cpu vector. Type requirements: Output iterator can be obtained via member function .begin() |
Definition at line 157 of file vector_proxy.hpp.
| void viennacl::fast_copy | ( | const const_vector_iterator< SCALARTYPE, ALIGNMENT > & | gpu_begin, |
| const const_vector_iterator< SCALARTYPE, ALIGNMENT > & | gpu_end, | ||
| CPU_ITERATOR | cpu_begin | ||
| ) |
| void viennacl::fast_copy | ( | CPU_ITERATOR const & | cpu_begin, |
| CPU_ITERATOR const & | cpu_end, | ||
| vector_iterator< SCALARTYPE, ALIGNMENT > | gpu_begin | ||
| ) |
| void viennacl::fast_copy | ( | NumericT * | cpu_matrix_begin, |
| NumericT * | cpu_matrix_end, | ||
| matrix< NumericT, F, AlignmentV > & | gpu_matrix | ||
| ) |
Copies a dense matrix from the host (CPU) to the OpenCL device (GPU or multi-core CPU) without temporary. Matrix-Layout on CPU must be equal to the matrix-layout on the GPU.
See Dense Matrix Type in the manual for the underlying data layout including padding rows and columns by zero.
| cpu_matrix_begin | Pointer to the first matrix entry. Cf. iterator concept in STL |
| cpu_matrix_end | Pointer past the last matrix entry. Cf. iterator concept in STL |
| gpu_matrix | A dense ViennaCL matrix |
Definition at line 1010 of file matrix.hpp.
| void viennacl::fast_copy | ( | const matrix< NumericT, F, AlignmentV > & | gpu_matrix, |
| NumericT * | cpu_matrix_begin | ||
| ) |
Copies a dense matrix from the OpenCL device (GPU or multi-core CPU) to the host (CPU).
See Dense Matrix Type in the manual for the underlying data layout including padding rows and columns by zero.
| gpu_matrix | A dense ViennaCL matrix |
| cpu_matrix_begin | Pointer to the output memory on the CPU. User must ensure that provided memory is large enough. |
Definition at line 1231 of file matrix.hpp.
| void viennacl::fast_copy | ( | const const_vector_iterator< NumericT, AlignmentV > & | gpu_begin, |
| const const_vector_iterator< NumericT, AlignmentV > & | gpu_end, | ||
| CPU_ITERATOR | cpu_begin | ||
| ) |
STL-like transfer of a GPU vector to the CPU. The cpu type is assumed to reside in a linear piece of memory, such as e.g. for std::vector.
This method is faster than the plain copy() function, because entries are directly written to the cpu vector, starting with &(*cpu.begin()) However, keep in mind that the cpu type MUST represent a linear piece of memory, otherwise you will run into undefined behavior.
| gpu_begin | GPU iterator pointing to the beginning of the gpu vector (STL-like) |
| gpu_end | GPU iterator pointing to the end of the vector (STL-like) |
| cpu_begin | Output iterator for the cpu vector. The cpu vector must be at least as long as the gpu vector! |
Definition at line 1234 of file vector.hpp.
| void viennacl::fast_copy | ( | vector_base< NumericT > const & | gpu_vec, |
| CPUVECTOR & | cpu_vec | ||
| ) |
Transfer from a gpu vector to a cpu vector. Convenience wrapper for viennacl::linalg::fast_copy(gpu_vec.begin(), gpu_vec.end(), cpu_vec.begin());.
| gpu_vec | A gpu vector. |
| cpu_vec | The cpu vector. Type requirements: Output iterator pointing to entries linear in memory can be obtained via member function .begin() |
Definition at line 1267 of file vector.hpp.
| void viennacl::fast_copy | ( | CPU_ITERATOR const & | cpu_begin, |
| CPU_ITERATOR const & | cpu_end, | ||
| vector_iterator< NumericT, AlignmentV > | gpu_begin | ||
| ) |
STL-like transfer of a CPU vector to the GPU. The cpu type is assumed to reside in a linear piece of memory, such as e.g. for std::vector.
This method is faster than the plain copy() function, because entries are directly read from the cpu vector, starting with &(*cpu.begin()). However, keep in mind that the cpu type MUST represent a linear piece of memory, otherwise you will run into undefined behavior.
| cpu_begin | CPU iterator pointing to the beginning of the cpu vector (STL-like) |
| cpu_end | CPU iterator pointing to the end of the vector (STL-like) |
| gpu_begin | Output iterator for the gpu vector. The gpu iterator must be incrementable (cpu_end - cpu_begin) times, otherwise the result is undefined. |
Definition at line 1400 of file vector.hpp.
| void viennacl::fast_copy | ( | const CPUVECTOR & | cpu_vec, |
| vector_base< NumericT > & | gpu_vec | ||
| ) |
Transfer from a cpu vector to a gpu vector. Convenience wrapper for viennacl::linalg::fast_copy(cpu_vec.begin(), cpu_vec.end(), gpu_vec.begin());.
| cpu_vec | A cpu vector. Type requirements: Iterator can be obtained via member function .begin() and .end() |
| gpu_vec | The gpu vector. |
Definition at line 1434 of file vector.hpp.
| vector<NumericT, AlignmentV>& viennacl::fast_swap | ( | vector< NumericT, AlignmentV > & | v1, |
| vector< NumericT, AlignmentV > & | v2 | ||
| ) |
Swaps the content of two vectors by swapping OpenCL handles only, NO data is copied.
| v1 | The first vector |
| v2 | The second vector |
Definition at line 1659 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_base<NumericT>, const S1, op_mult>>::type viennacl::operator* | ( | S1 const & | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a host scalar (float or double) and m1 is a ViennaCL matrix.
| value | The host scalar (float or double) |
| m1 | A ViennaCL matrix |
Definition at line 1374 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | char | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a char (8-bit integer)
Definition at line 1382 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | short | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a short integer.
Definition at line 1390 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | int | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is an integer.
Definition at line 1398 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | long | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a long integer.
Definition at line 1406 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | float | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a single precision floating point value.
Definition at line 1414 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | double | value, |
| matrix_base< NumericT > const & | m1 | ||
| ) |
Operator overload for the expression alpha * m1, where alpha is a double precision floating point value.
Definition at line 1422 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_expression< LHS, RHS, OP>, const S1, op_mult> >::type viennacl::operator* | ( | matrix_expression< LHS, RHS, OP > const & | proxy, |
| S1 const & | val | ||
| ) |
Operator overload for the multiplication of a matrix expression with a scalar from the right, e.g. (beta * m1) * alpha. Here, beta * m1 is wrapped into a matrix_expression and then multiplied with alpha from the right.
| proxy | Left hand side matrix expression |
| val | Right hand side scalar |
Definition at line 1437 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_expression< LHS, RHS, OP>, const S1, op_mult> >::type viennacl::operator* | ( | S1 const & | val, |
| matrix_expression< LHS, RHS, OP > const & | proxy | ||
| ) |
Operator overload for the multiplication of a matrix expression with a ViennaCL scalar from the left, e.g. alpha * (beta * m1). Here, beta * m1 is wrapped into a matrix_expression and then multiplied with alpha from the left.
| val | Right hand side scalar |
| proxy | Left hand side matrix expression |
Definition at line 1452 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_base<NumericT>, const S1, op_mult> >::type viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| S1 const & | s1 | ||
| ) |
Scales the matrix by a GPU scalar 'alpha' and returns an expression template.
Definition at line 1463 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| char | s1 | ||
| ) |
Scales the matrix by a char (8-bit integer) 'alpha' and returns an expression template.
Definition at line 1471 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| short | s1 | ||
| ) |
Scales the matrix by a short integer 'alpha' and returns an expression template.
Definition at line 1479 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| int | s1 | ||
| ) |
Scales the matrix by an integer 'alpha' and returns an expression template.
Definition at line 1487 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| long | s1 | ||
| ) |
Scales the matrix by a long integer 'alpha' and returns an expression template.
Definition at line 1495 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| float | s1 | ||
| ) |
Scales the matrix by a single precision floating point number 'alpha' and returns an expression template.
Definition at line 1503 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_mult> viennacl::operator* | ( | matrix_base< NumericT > const & | m1, |
| double | s1 | ||
| ) |
Scales the matrix by a double precision floating point number 'alpha' and returns an expression template.
Definition at line 1511 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_scalar<S1>::value,viennacl::matrix_expression< const viennacl::matrix_expression< const vector_base<NumericT>, const vector_base<NumericT>, op_prod>,const S1,op_mult>>::type viennacl::operator* | ( | const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy, |
| const S1 & | val | ||
| ) |
Definition at line 1752 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_cpu_scalar<S1>::value,viennacl::matrix_expression< const viennacl::matrix_expression< const vector_base<NumericT>, const vector_base<NumericT>, op_prod>,const NumericT,op_mult>>::type viennacl::operator* | ( | const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy, |
| const S1 & | val | ||
| ) |
Definition at line 1766 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_scalar<S1>::value,viennacl::matrix_expression< const viennacl::matrix_expression< const vector_base<NumericT>, const vector_base<NumericT>, op_prod>,const S1,op_mult>>::type viennacl::operator* | ( | const S1 & | val, |
| const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Definition at line 1781 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_cpu_scalar<S1>::value,viennacl::matrix_expression< const viennacl::matrix_expression< const vector_base<NumericT>, const vector_base<NumericT>, op_prod>,const NumericT,op_mult>>::type viennacl::operator* | ( | const S1 & | val, |
| const viennacl::matrix_expression< const vector_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Definition at line 1795 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,vector_expression< const vector_base<T>, const S1, op_mult> >::type viennacl::operator* | ( | S1 const & | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a host scalar (float or double) and v1 is a ViennaCL vector.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1871 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | char | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a char.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1883 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | short | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a short.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1895 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | int | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a int.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1907 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | long | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a long.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1919 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | float | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a float.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1931 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | double | value, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a double.
| value | The host scalar (float or double) |
| vec | A ViennaCL vector |
Definition at line 1943 of file vector.hpp.
| vector_expression< const vector_base<T>, const scalar_expression<LHS, RHS, OP>, op_mult> viennacl::operator* | ( | scalar_expression< LHS, RHS, OP > const & | expr, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the expression alpha * v1, where alpha is a scalar expression and v1 is a ViennaCL vector.
| expr | The scalar expression |
| vec | A ViennaCL vector |
Definition at line 1957 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,vector_expression< const vector_base<T>, const S1, op_mult> >::type viennacl::operator* | ( | vector_base< T > const & | vec, |
| S1 const & | value | ||
| ) |
Scales the vector by a scalar 'alpha' and returns an expression template.
Definition at line 1967 of file vector.hpp.
| vector_expression< const vector_base<T>, const T, op_mult> viennacl::operator* | ( | vector_base< T > const & | vec, |
| T const & | value | ||
| ) |
Definition at line 1974 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,viennacl::vector_expression<const vector_expression<LHS, RHS, OP>, const S1, op_mult> >::type viennacl::operator* | ( | vector_expression< LHS, RHS, OP > const & | proxy, |
| S1 const & | val | ||
| ) |
Operator overload for the multiplication of a vector expression with a scalar from the right, e.g. (beta * vec1) * alpha. Here, beta * vec1 is wrapped into a vector_expression and then multiplied with alpha from the right.
| proxy | Left hand side vector expression |
| val | Right hand side scalar |
Definition at line 1987 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,viennacl::vector_expression<const vector_expression<LHS, RHS, OP>, const S1, op_mult> >::type viennacl::operator* | ( | S1 const & | val, |
| vector_expression< LHS, RHS, OP > const & | proxy | ||
| ) |
Operator overload for the multiplication of a vector expression with a ViennaCL scalar from the left, e.g. alpha * (beta * vec1). Here, beta * vec1 is wrapped into a vector_expression and then multiplied with alpha from the left.
| val | Right hand side scalar |
| proxy | Left hand side vector expression |
Definition at line 2001 of file vector.hpp.
| viennacl::enable_if< viennacl::is_scalar<S1>::value, matrix_base<NumericT> & >::type viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| S1 const & | gpu_val | ||
| ) |
Scales a matrix by a GPU scalar value.
Definition at line 1522 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| char | gpu_val | ||
| ) |
Scales a matrix by a char (8-bit) value.
Definition at line 1533 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| short | gpu_val | ||
| ) |
Scales a matrix by a short integer value.
Definition at line 1543 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| int | gpu_val | ||
| ) |
Scales a matrix by an integer value.
Definition at line 1553 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| long | gpu_val | ||
| ) |
Scales a matrix by a long integer value.
Definition at line 1563 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| float | gpu_val | ||
| ) |
Scales a matrix by a single precision floating point value.
Definition at line 1573 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator*= | ( | matrix_base< NumericT > & | m1, |
| double | gpu_val | ||
| ) |
Scales a matrix by a double precision floating point value.
Definition at line 1583 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,vector_base<T> &>::type viennacl::operator*= | ( | vector_base< T > & | v1, |
| S1 const & | gpu_val | ||
| ) |
Scales this vector by a GPU scalar value.
Definition at line 1686 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_sparse_matrix<SparseMatrixType>::value, viennacl::vector<SCALARTYPE> >::type viennacl::operator+ | ( | viennacl::vector_base< SCALARTYPE > & | result, |
| const viennacl::vector_expression< const SparseMatrixType, const viennacl::vector_base< SCALARTYPE >, viennacl::op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 + A * v2', where A is a matrix.
| result | The vector the result is written to. |
| proxy | An expression template proxy class holding v1, A, and v2. |
Definition at line 390 of file sparse_matrix_operations.hpp.
| viennacl::vector<NumericT> viennacl::operator+ | ( | const vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 + A * v2', where A is a matrix.
| v1 | The addend vector. |
| proxy | An expression template proxy class. |
Definition at line 1182 of file matrix_operations.hpp.
| matrix_expression< const matrix_expression<const LHS1, const RHS1, OP1>,const matrix_expression<const LHS2, const RHS2, OP2>,op_add> viennacl::operator+ | ( | matrix_expression< const LHS1, const RHS1, OP1 > const & | proxy1, |
| matrix_expression< const LHS2, const RHS2, OP2 > const & | proxy2 | ||
| ) |
Generic 'catch-all' overload, which enforces a temporary if the expression tree gets too deep.
Definition at line 1249 of file matrix.hpp.
| matrix_expression< const matrix_expression<const LHS1, const RHS1, OP1>,const matrix_base<NumericT>,op_add> viennacl::operator+ | ( | matrix_expression< const LHS1, const RHS1, OP1 > const & | proxy1, |
| matrix_base< NumericT > const & | proxy2 | ||
| ) |
Definition at line 1265 of file matrix.hpp.
| vector<NumericT> viennacl::operator+ | ( | const vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 + A * v2', where A is a matrix.
| v1 | The addend vector. |
| proxy | An expression template proxy class. |
Definition at line 1266 of file matrix_operations.hpp.
| matrix_expression< const matrix_base<NumericT>,const matrix_expression<const LHS2, const RHS2, OP2>,op_add> viennacl::operator+ | ( | matrix_base< NumericT > const & | proxy1, |
| matrix_expression< const LHS2, const RHS2, OP2 > const & | proxy2 | ||
| ) |
Definition at line 1281 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const matrix_base<NumericT>, op_add > viennacl::operator+ | ( | const matrix_base< NumericT > & | m1, |
| const matrix_base< NumericT > & | m2 | ||
| ) |
Operator overload for m1 + m2, where m1 and m2 are either dense matrices, matrix ranges, or matrix slices. No mixing of different storage layouts allowed at the moment.
Definition at line 1295 of file matrix.hpp.
| vector_expression< const vector_expression< LHS1, RHS1, OP1>,const vector_expression< LHS2, RHS2, OP2>,viennacl::op_add> viennacl::operator+ | ( | vector_expression< LHS1, RHS1, OP1 > const & | proxy1, |
| vector_expression< LHS2, RHS2, OP2 > const & | proxy2 | ||
| ) |
Operator overload for the addition of two vector expressions.
| proxy1 | Left hand side vector expression |
| proxy2 | Right hand side vector expression |
Definition at line 1732 of file vector.hpp.
| vector_expression< const vector_expression<LHS, RHS, OP>,const vector_base<T>,viennacl::op_add> viennacl::operator+ | ( | vector_expression< LHS, RHS, OP > const & | proxy, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the addition of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created.
| proxy | Left hand side vector expression |
| vec | Right hand side vector (also -range and -slice is allowed) |
Definition at line 1750 of file vector.hpp.
| vector_expression< const vector_base<T>,const vector_expression<LHS, RHS, OP>,viennacl::op_add> viennacl::operator+ | ( | vector_base< T > const & | vec, |
| vector_expression< LHS, RHS, OP > const & | proxy | ||
| ) |
Operator overload for the addition of a vector with a vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created.
| proxy | Left hand side vector expression |
| vec | Right hand side vector (also -range and -slice is allowed) |
Definition at line 1768 of file vector.hpp.
| vector_expression< const vector_base<T>, const vector_base<T>, op_add> viennacl::operator+ | ( | const vector_base< T > & | v1, |
| const vector_base< T > & | v2 | ||
| ) |
Returns an expression template object for adding up two vectors, i.e. v1 + v2.
Definition at line 1781 of file vector.hpp.
| vector<NumericT> viennacl::operator+= | ( | vector_base< NumericT > & | v1, |
| const viennacl::vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, viennacl::op_prod > & | proxy | ||
| ) |
Implementation of the operation v1 += A * v2, where A is a matrix.
| v1 | The result vector v1 where A * v2 is added to |
| proxy | An expression template proxy class. |
Definition at line 1141 of file matrix_operations.hpp.
| vector<NumericT> viennacl::operator+= | ( | vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation v1 += A * v2, where A is a matrix.
| v1 | The addend vector where the result is written to. |
| proxy | An expression template proxy class. |
Definition at line 1223 of file matrix_operations.hpp.
| vector_base<T>& viennacl::operator+= | ( | vector_base< T > & | v1, |
| const vector_expression< const LHS, const RHS, OP > & | proxy | ||
| ) |
Definition at line 1280 of file vector_operations.hpp.
| viennacl::enable_if< viennacl::is_any_sparse_matrix<SparseMatrixType>::value, viennacl::vector<SCALARTYPE> >::type viennacl::operator- | ( | viennacl::vector_base< SCALARTYPE > & | result, |
| const viennacl::vector_expression< const SparseMatrixType, const viennacl::vector_base< SCALARTYPE >, viennacl::op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 - A * v2', where A is a matrix.
| result | The vector the result is written to. |
| proxy | An expression template proxy class. |
Definition at line 408 of file sparse_matrix_operations.hpp.
| viennacl::vector<NumericT> viennacl::operator- | ( | const vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 - A * v2', where A is a matrix.
| v1 | The addend vector. |
| proxy | An expression template proxy class. |
Definition at line 1200 of file matrix_operations.hpp.
| vector<NumericT> viennacl::operator- | ( | const vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation 'result = v1 - A * v2', where A is a matrix.
| v1 | The addend vector. |
| proxy | An expression template proxy class. |
Definition at line 1286 of file matrix_operations.hpp.
| matrix_expression< const matrix_expression<const LHS1, const RHS1, OP1>,const matrix_expression<const LHS2, const RHS2, OP2>,op_sub> viennacl::operator- | ( | matrix_expression< const LHS1, const RHS1, OP1 > const & | proxy1, |
| matrix_expression< const LHS2, const RHS2, OP2 > const & | proxy2 | ||
| ) |
Definition at line 1309 of file matrix.hpp.
| matrix_expression< const matrix_expression<const LHS1, const RHS1, OP1>,const matrix_base<NumericT>,op_sub> viennacl::operator- | ( | matrix_expression< const LHS1, const RHS1, OP1 > const & | proxy1, |
| matrix_base< NumericT > const & | proxy2 | ||
| ) |
Definition at line 1325 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>,const matrix_expression<const LHS2, const RHS2, OP2>,op_sub> viennacl::operator- | ( | matrix_base< NumericT > const & | proxy1, |
| matrix_expression< const LHS2, const RHS2, OP2 > const & | proxy2 | ||
| ) |
Definition at line 1341 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const matrix_base<NumericT>, op_sub > viennacl::operator- | ( | const matrix_base< NumericT > & | m1, |
| const matrix_base< NumericT > & | m2 | ||
| ) |
Operator overload for m1 - m2, where m1 and m2 are either dense matrices, matrix ranges, or matrix slices. No mixing of different storage layouts allowed at the moment.
Definition at line 1355 of file matrix.hpp.
| vector_expression< const vector_expression< LHS1, RHS1, OP1>,const vector_expression< LHS2, RHS2, OP2>,viennacl::op_sub> viennacl::operator- | ( | vector_expression< LHS1, RHS1, OP1 > const & | proxy1, |
| vector_expression< LHS2, RHS2, OP2 > const & | proxy2 | ||
| ) |
Operator overload for the subtraction of two vector expressions.
| proxy1 | Left hand side vector expression |
| proxy2 | Right hand side vector expression |
Definition at line 1802 of file vector.hpp.
| vector_expression< const vector_expression<LHS, RHS, OP>,const vector_base<T>,viennacl::op_sub> viennacl::operator- | ( | vector_expression< LHS, RHS, OP > const & | proxy, |
| vector_base< T > const & | vec | ||
| ) |
Operator overload for the subtraction of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created.
| proxy | Left hand side vector expression |
| vec | Right hand side vector (also -range and -slice is allowed) |
Definition at line 1821 of file vector.hpp.
| vector_expression< const vector_base<T>,const vector_expression<LHS, RHS, OP>,viennacl::op_sub> viennacl::operator- | ( | vector_base< T > const & | vec, |
| vector_expression< LHS, RHS, OP > const & | proxy | ||
| ) |
Operator overload for the subtraction of a vector expression with a vector or another vector expression. This is the default implementation for all cases that are too complex in order to be covered within a single kernel, hence a temporary vector is created.
| proxy | Left hand side vector expression |
| vec | Right hand side vector (also -range and -slice is allowed) |
Definition at line 1839 of file vector.hpp.
| vector_expression< const vector_base<T>, const vector_base<T>, op_sub> viennacl::operator- | ( | const vector_base< T > & | v1, |
| const vector_base< T > & | v2 | ||
| ) |
Returns an expression template object for subtracting two vectors, i.e. v1 - v2.
Definition at line 1852 of file vector.hpp.
| vector<NumericT> viennacl::operator-= | ( | vector_base< NumericT > & | v1, |
| const viennacl::vector_expression< const matrix_base< NumericT >, const vector_base< NumericT >, viennacl::op_prod > & | proxy | ||
| ) |
Implementation of the operation v1 -= A * v2, where A is a matrix.
| v1 | The result vector v1 where A * v2 is subtracted from |
| proxy | An expression template proxy class. |
Definition at line 1159 of file matrix_operations.hpp.
| vector<NumericT> viennacl::operator-= | ( | vector_base< NumericT > & | v1, |
| const vector_expression< const matrix_expression< const matrix_base< NumericT >, const matrix_base< NumericT >, op_trans >, const vector_base< NumericT >, op_prod > & | proxy | ||
| ) |
Implementation of the operation v1 -= A * v2, where A is a matrix.
| v1 | The addend vector where the result is written to. |
| proxy | An expression template proxy class. |
Definition at line 1244 of file matrix_operations.hpp.
| vector_base<T>& viennacl::operator-= | ( | vector_base< T > & | v1, |
| const vector_expression< const LHS, const RHS, OP > & | proxy | ||
| ) |
Definition at line 1291 of file vector_operations.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_expression<const LHS, const RHS, OP>, const S1, op_div> >::type viennacl::operator/ | ( | matrix_expression< const LHS, const RHS, OP > const & | proxy, |
| S1 const & | val | ||
| ) |
Operator overload for the division of a matrix expression by a scalar from the right, e.g. (beta * m1) / alpha. Here, beta * m1 is wrapped into a matrix_expression and then divided by alpha.
| proxy | Left hand side matrix expression |
| val | Right hand side scalar |
Definition at line 1603 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,matrix_expression< const matrix_base<NumericT>, const S1, op_div> >::type viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| S1 const & | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a GPU scalar 'alpha'.
Definition at line 1614 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| char | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a char (8-bit integer) 'alpha'.
Definition at line 1622 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| short | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a short integer 'alpha'.
Definition at line 1630 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| int | s1 | ||
| ) |
Returns an expression template for scaling the matrix by an integer 'alpha'.
Definition at line 1638 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| long | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a long integer 'alpha'.
Definition at line 1646 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| float | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a single precision floating point number 'alpha'.
Definition at line 1654 of file matrix.hpp.
| matrix_expression< const matrix_base<NumericT>, const NumericT, op_div> viennacl::operator/ | ( | matrix_base< NumericT > const & | m1, |
| double | s1 | ||
| ) |
Returns an expression template for scaling the matrix by a double precision floating point number 'alpha'.
Definition at line 1662 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,viennacl::vector_expression<const vector_expression<LHS, RHS, OP>, const S1, op_div> >::type viennacl::operator/ | ( | vector_expression< LHS, RHS, OP > const & | proxy, |
| S1 const & | val | ||
| ) |
Operator overload for the division of a vector expression by a scalar from the right, e.g. (beta * vec1) / alpha. Here, beta * vec1 is wrapped into a vector_expression and then divided by alpha.
| proxy | Left hand side vector expression |
| val | Right hand side scalar |
Definition at line 2019 of file vector.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,vector_expression< const vector_base<T>, const S1, op_div> >::type viennacl::operator/ | ( | vector_base< T > const & | v1, |
| S1 const & | s1 | ||
| ) |
Returns an expression template for scaling the vector by a GPU scalar 'alpha'.
Definition at line 2031 of file vector.hpp.
| viennacl::enable_if< viennacl::is_scalar<S1>::value, matrix_base<NumericT> & >::type viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| S1 const & | gpu_val | ||
| ) |
Scales a matrix by a GPU scalar value.
Definition at line 1674 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| char | gpu_val | ||
| ) |
Scales a matrix by a char (8-bit integer) value.
Definition at line 1684 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| short | gpu_val | ||
| ) |
Scales a matrix by a short integer value.
Definition at line 1694 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| int | gpu_val | ||
| ) |
Scales a matrix by an integer value.
Definition at line 1704 of file matrix.hpp.
| viennacl::enable_if< viennacl::is_any_scalar<S1>::value,vector_base<T> &>::type viennacl::operator/= | ( | vector_base< T > & | v1, |
| S1 const & | gpu_val | ||
| ) |
Scales this vector by a GPU scalar value.
Definition at line 1707 of file vector.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| long | gpu_val | ||
| ) |
Scales a matrix by a long integer value.
Definition at line 1714 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| float | gpu_val | ||
| ) |
Scales a matrix by a single precision floating point value.
Definition at line 1724 of file matrix.hpp.
| matrix_base<NumericT>& viennacl::operator/= | ( | matrix_base< NumericT > & | m1, |
| double | gpu_val | ||
| ) |
Scales a matrix by a double precision floating point value.
Definition at line 1734 of file matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| vandermonde_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Prints the matrix. Output is compatible to boost::numeric::ublas.
| s | STL output stream |
| gpu_matrix | A ViennaCL Vandermonde matrix |
Definition at line 225 of file vandermonde_matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| hankel_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Definition at line 226 of file hankel_matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| circulant_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Prints the matrix. Output is compatible to boost::numeric::ublas.
| s | STL output stream |
| gpu_matrix | A ViennaCL circulant matrix |
Definition at line 241 of file circulant_matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| toeplitz_matrix< NumericT, AlignmentV > & | gpu_matrix | ||
| ) |
Prints the matrix. Output is compatible to boost::numeric::ublas.
| s | STL output stream |
| gpu_matrix | A ViennaCL Toeplitz matrix |
Definition at line 267 of file toeplitz_matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| const matrix_base< NumericT > & | gpu_matrix | ||
| ) |
Prints the matrix. Output is compatible to boost::numeric::ublas.
| s | STL output stream |
| gpu_matrix | A dense ViennaCL matrix |
Definition at line 828 of file matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| const scalar< NumericT > & | val | ||
| ) |
Allows to directly print the value of a scalar to an output stream.
Definition at line 855 of file scalar.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | s, |
| const matrix_expression< LHS, RHS, OP > & | expr | ||
| ) |
Prints the matrix. Output is compatible to boost::numeric::ublas.
| s | STL output stream |
| expr | A matrix expression |
Definition at line 865 of file matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | os, |
| compressed_matrix< NumericT, AlignmentV > const & | A | ||
| ) |
Output stream support for compressed_matrix. Output format is same as MATLAB, Octave, or SciPy.
| os | STL output stream |
| A | The compressed matrix to be printed. |
Definition at line 1059 of file compressed_matrix.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | os, |
| vector_base< T > const & | val | ||
| ) |
Output stream. Output format is ublas compatible.
| os | STL output stream |
| val | The vector that should be printed |
Definition at line 1617 of file vector.hpp.
| std::ostream& viennacl::operator<< | ( | std::ostream & | os, |
| vector_expression< LHS, RHS, OP > const & | proxy | ||
| ) |
Definition at line 1633 of file vector.hpp.
| std::istream& viennacl::operator>> | ( | std::istream & | s, |
| const scalar< NumericT > & | val | ||
| ) |
Allows to directly read a value of a scalar from an input stream.
Definition at line 864 of file scalar.hpp.
| vector_range<VectorType> viennacl::project | ( | VectorType const & | vec, |
| viennacl::range const & | r1 | ||
| ) |
Definition at line 169 of file vector_proxy.hpp.
| vector_range<VectorType> viennacl::project | ( | viennacl::vector_range< VectorType > const & | vec, |
| viennacl::range const & | r1 | ||
| ) |
Definition at line 175 of file vector_proxy.hpp.
| vector_slice<VectorType> viennacl::project | ( | VectorType const & | vec, |
| viennacl::slice const & | s1 | ||
| ) |
Definition at line 308 of file vector_proxy.hpp.
| vector_slice<VectorType> viennacl::project | ( | viennacl::vector_slice< VectorType > const & | vec, |
| viennacl::slice const & | s1 | ||
| ) |
Definition at line 315 of file vector_proxy.hpp.
| vector_slice<VectorType> viennacl::project | ( | viennacl::vector_slice< VectorType > const & | vec, |
| viennacl::range const & | r1 | ||
| ) |
Definition at line 324 of file vector_proxy.hpp.
| matrix_range<MatrixType> viennacl::project | ( | MatrixType const & | A, |
| viennacl::range const & | r1, | ||
| viennacl::range const & | r2 | ||
| ) |
Definition at line 326 of file matrix_proxy.hpp.
| vector_slice<VectorType> viennacl::project | ( | viennacl::vector_range< VectorType > const & | vec, |
| viennacl::slice const & | s1 | ||
| ) |
Definition at line 331 of file vector_proxy.hpp.
| matrix_range<MatrixType> viennacl::project | ( | matrix_range< MatrixType > const & | A, |
| viennacl::range const & | r1, | ||
| viennacl::range const & | r2 | ||
| ) |
Definition at line 335 of file matrix_proxy.hpp.
| matrix_slice<MatrixType> viennacl::project | ( | MatrixType const & | A, |
| viennacl::slice const & | r1, | ||
| viennacl::slice const & | r2 | ||
| ) |
Definition at line 568 of file matrix_proxy.hpp.
| matrix_slice<MatrixType> viennacl::project | ( | matrix_range< MatrixType > const & | A, |
| viennacl::slice const & | r1, | ||
| viennacl::slice const & | r2 | ||
| ) |
Definition at line 576 of file matrix_proxy.hpp.
| matrix_slice<MatrixType> viennacl::project | ( | matrix_slice< MatrixType > const & | A, |
| viennacl::slice const & | r1, | ||
| viennacl::slice const & | r2 | ||
| ) |
Definition at line 584 of file matrix_proxy.hpp.
| std::vector<int> viennacl::reorder | ( | MatrixType const & | matrix, |
| gibbs_poole_stockmeyer_tag | |||
| ) |
Function for the calculation of a node numbering permutation vector to reduce the bandwidth of a incidence matrix by the Gibbs-Poole-Stockmeyer algorithm.
references: Werner Neudorf: "Bandbreitenreduktion - Teil 3. Algorithmus von Gibbs-Poole-Stockmeyer. Testbeispiele mit CM und GPS", Preprint No. M 08/02, September 2002. Technische Universität Ilmenau, Fakultät für Mathematik und Naturwissenschaften, Institut für Mathematik. http://www.db-thueringen.de/servlets/DerivateServlet/Derivate-8673/IfM_Preprint_M_02_08.pdf (URL taken on June 14, 2011)
| matrix | vector of n matrix rows, where each row is a map<int, double> containing only the nonzero elements |
Definition at line 150 of file gibbs_poole_stockmeyer.hpp.
| std::vector<IndexT> viennacl::reorder | ( | std::vector< std::map< IndexT, ValueT > > const & | matrix, |
| cuthill_mckee_tag | |||
| ) |
Function for the calculation of a node number permutation to reduce the bandwidth of an incidence matrix by the Cuthill-McKee algorithm.
references: Algorithm was implemented similary as described in "Tutorial: Bandwidth Reduction - The CutHill- McKee Algorithm" posted by Ciprian Zavoianu as weblog at http://ciprian-zavoianu.blogspot.com/2009/01/project-bandwidth-reduction.html on January 15, 2009 (URL taken on June 14, 2011)
| matrix | vector of n matrix rows, where each row is a map<int, double> containing only the nonzero elements |
Definition at line 367 of file cuthill_mckee.hpp.
| std::vector<IndexT> viennacl::reorder | ( | std::vector< std::map< IndexT, ValueT > > const & | matrix, |
| advanced_cuthill_mckee_tag const & | tag | ||
| ) |
Function for the calculation of a node number permutation to reduce the bandwidth of an incidence matrix by the advanced Cuthill-McKee algorithm.
references: see description of original Cuthill McKee implementation, and E. Cuthill and J. McKee: "Reducing the Bandwidth of sparse symmetric Matrices". Naval Ship Research and Development Center, Washington, D. C., 20007
Definition at line 474 of file cuthill_mckee.hpp.
| vector_expression< const matrix_base<NumericT, F>, const unsigned int, op_row> viennacl::row | ( | const matrix_base< NumericT, F > & | A, |
| unsigned int | i | ||
| ) |
Definition at line 910 of file matrix.hpp.
| void viennacl::swap | ( | vector_base< T > & | vec1, |
| vector_base< T > & | vec2 | ||
| ) |
Swaps the contents of two vectors, data is copied.
| vec1 | The first vector |
| vec2 | The second vector |
Definition at line 1648 of file vector.hpp.
| void viennacl::switch_memory_context | ( | T & | obj, |
| viennacl::context | new_ctx | ||
| ) |
Generic convenience routine for migrating data of an object to a new memory domain.
Definition at line 622 of file memory.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > const & | v0, |
| vector_base< ScalarT > const & | v1 | ||
| ) |
Definition at line 1155 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > & | v0, |
| vector_base< ScalarT > & | v1 | ||
| ) |
Definition at line 1158 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > const & | v0, |
| vector_base< ScalarT > const & | v1, | ||
| vector_base< ScalarT > const & | v2 | ||
| ) |
Definition at line 1162 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > & | v0, |
| vector_base< ScalarT > & | v1, | ||
| vector_base< ScalarT > & | v2 | ||
| ) |
Definition at line 1165 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > const & | v0, |
| vector_base< ScalarT > const & | v1, | ||
| vector_base< ScalarT > const & | v2, | ||
| vector_base< ScalarT > const & | v3 | ||
| ) |
Definition at line 1169 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > & | v0, |
| vector_base< ScalarT > & | v1, | ||
| vector_base< ScalarT > & | v2, | ||
| vector_base< ScalarT > & | v3 | ||
| ) |
Definition at line 1175 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > const & | v0, |
| vector_base< ScalarT > const & | v1, | ||
| vector_base< ScalarT > const & | v2, | ||
| vector_base< ScalarT > const & | v3, | ||
| vector_base< ScalarT > const & | v4 | ||
| ) |
Definition at line 1182 of file vector.hpp.
| vector_tuple<ScalarT> viennacl::tie | ( | vector_base< ScalarT > & | v0, |
| vector_base< ScalarT > & | v1, | ||
| vector_base< ScalarT > & | v2, | ||
| vector_base< ScalarT > & | v3, | ||
| vector_base< ScalarT > & | v4 | ||
| ) |
Definition at line 1199 of file vector.hpp.
| viennacl::enable_if<viennacl::is_any_sparse_matrix<M1>::value, matrix_expression< const M1, const M1, op_trans> >::type viennacl::trans | ( | const M1 & | mat | ) |
Returns an expression template class representing a transposed matrix.
Definition at line 376 of file sparse_matrix_operations.hpp.
| matrix_expression< const matrix_base<NumericT>, const matrix_base<NumericT>, op_trans> viennacl::trans | ( | const matrix_base< NumericT > & | mat | ) |
Returns an expression template class representing a transposed matrix.
Definition at line 877 of file matrix.hpp.
| matrix_expression< const matrix_expression<const LhsT, const RhsT, OpT>, const matrix_expression<const LhsT, const RhsT, OpT>, op_trans> viennacl::trans | ( | const matrix_expression< const LhsT, const RhsT, OpT > & | proxy | ) |
Returns an expression template class representing the transposed matrix expression.
Definition at line 885 of file matrix.hpp.
 1.8.6
1.8.6